
Klustron CDC 并行复制及高可用
Klustron CDC 并行复制及高可用
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见:http://doc.klustron.com/zh/Release_notes.html。
本文内容:
之前已有文章描述了利用Klustron数据库CDC模块,实现MySQL与Klustron之间的双向数据复制的功能,实际上Klustron还有更高级的一些用法和功能实现,本文将覆盖两个新的特性:CDC服务高可用及CDC并行复制技术。
在本文中,我们将演示完成上述两种新功能场景。
01 环境准备
本文所指的测试场景中,涉及使用CDC进行MySQL与Klustron之间的双向复制测试,所以,需要准备一个MySQL的实例环境,另外再准备一套Klustron的运行环境,理论上,需要4台服务器,1台用于MySQL安装,3台用于Klustron环境,受限于资源有限,故使用3台机器搭建整个测试环境,因为使用了不同的Linux帐户,不同的服务端口,所以不存在环境冲突。
1.1 MySQL服务器安装配置
《略》,具体请参考MySQL社区版安装文档。
MySQL 版本:MySQL 8.0.34
IP:192.168.0.155
端口:3306
Linux:Ubuntu 20.04.2
说明:要完成MySQL向Klustron进行同步,MySQL需要启用binlog(8.0已默认开启),并且同时启用GTID,按如下指令完成设置:
root@kunlun3:~# mysql -h 192.168.0.155 -P 3306 -u root -p
mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = WARN;
mysql> SET @@GLOBAL.ENFORCE_GTID_CONSISTENCY = ON;
mysql> SET @@GLOBAL.GTID_MODE = OFF_PERMISSIVE;
mysql> SET @@GLOBAL.GTID_MODE = ON_PERMISSIVE;
mysql> SET @@GLOBAL.GTID_MODE = ON;
mysql> SET PERSIST GTID_MODE = on ;
mysql> SET PERSIST ENFORCE_GTID_CONSISTENCY = on ;
mysql> SET PERSIST binlog_row_metadata='FULL';
mysql> SET PERSIST binlog_row_image='FULL';
退出mysql,重启MySQL服务,使参数生效:
systemctl restart mysqld
1.2 Klustron 安装配置
《略》
Klustron 环境说明:
XPanel: http://192.168.0.152:40180/KunlunXPanel/#/cluster
计算节点:192.168.0.155 ,端口: 47001
存储节点(shard1):192.168.0.153, 端口:57005 (主)
存储节点(shard2):192.168.0.152, 端口:57003 (主)
Klustron 安装在kl用户下
1.3 CDC 安装配置
从[http://zettatech.tpddns.cn:14000/dailybuilds/enterprise/kunlun-cdc-1.3.1.tgz 下载文件kunlun-cdc-1.3.1.tgz](http://zettatech.tpddns.cn:14000/dailybuilds/enterprise/kunlun-cdc-1.3.1.tgz 下载文件kunlun-cdc-1.3.1.tgz) 释放到192.168.0.152 / 153/ 155 3台机的kl用户的home目录下,直接用tar -zxvf kunlun-cdc-1.3.1.tgz 解开该文件,在此目录下,会生成名为:
/home/kl/kunlun-cdc-1.3.1,及相关的子目录,形式如下:

用kl用户进入192.168.0.152 / 192.168.0.153/ 192.168.0.155 的conf目录,编辑参数文件:kunlun_cdc.cnf
cd /home/kl/kunlun-cdc-1.3.1/conf
vi kunlun_cdc.cnf
修改如下参数:
local_ip = 192.168.0.153 #3台机各自的IP
http_port = 18012 #3台机取一致的端口,实际可以不一致,按需定义
ha_group_member = 192.168.0.152:18081,192.168.0.153:18081,192.168.0.155:18081 #3台机组成一个CDC的高可用集群,端口自定义,本例取18081
server_id = 2 #3台机各自定义一个自已的ID号,不唯一即可
保存退出。
进入3台机的CDC bin目录,该目录下有用于启停CDC服务的命令:
start_kunlun_cdc.sh stop_kunlun_cdc.sh
在3台机执行如下指令,启动CDC服务
cd /home/kl/kunlun-cdc-1.3.1/bin
./start_kunlun_cdc.sh
ps -ef |grep cdc
输出如下信息,说明启动CDC服务成功

登陆到XPanel,http:// 192.168.0.152:40180/KunlunXPanel/#/cdc/list,将打开如下页面:

点击“新增”配置“CDC服务”,输入如下相应的参数,

分组号可以自定义,本例中取分组号为1,因为在本例中是配置了3台CDC服务器组成高可用集群,所以,需要点击上图中右侧的“+”号继续完成剩余两个CDC服务的配置信息添加工作,并完成后点击“确认”进行保存。

保存后,界面效果如下所示:

注意:其中192.168.0.152在“主节点”字段显示为1,意味着当前承担CDC服务的节点是它,其他两个节点作为备节点,在主节点失效的时候,会选择其中一个升级为主节点,继续服务CDC相关的任务。
02 CDC 测试
2.1 CDC高可用测试(验证场景:从MySQL向Klustron同步数据)
先在MySQL中建立源库相应的数据库,用户,表,按如下指令创建相应对象:
root@kunlun3:~# mysql -h 192.168.0.155 -P 3306 -u root -p
mysql> CREATE USER 'repl'@'%' IDENTIFIED WITH mysql_native_password BY 'repl';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
mysql> create database test ;
mysql> create user 'test'@'%' identified by 'test';
mysql> grant all on test.* to 'test'@'%';
mysql> flush privileges;
mysql> exit;
root@kunlun3:~# mysql -h 192.168.0.155 -P 3306 -u test -p test
mysql>create table target1 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
mysql>create table target2 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
mysql>create table source (pk int primary key, txt1 text , txt2 text ,txt3 text ) ;
mysql>CREATE TEMPORARY TABLE IF NOT EXISTS series (n INT);
mysql> DELIMITER //
mysql>CREATE PROCEDURE fill_series()
BEGIN
DECLARE i INT DEFAULT 1;
-- 生成5000条记录
WHILE i <= 5000 DO
INSERT INTO series VALUES (i);
SET i = i + 1;
END WHILE;
END //
mysql>DELIMITER ;
-- 调用过程来生成序列
mysql>CALL fill_series();
mysql>truncate table source ;
mysql>INSERT INTO source SELECT n, RPAD('a', 4000, 'a'),RPAD('b', 4000, 'b'),RPAD('c', 4000, 'c') FROM series;
mysql>DROP TEMPORARY TABLE IF EXISTS series;
mysql>DROP PROCEDURE IF EXISTS fill_series;

连接Klustron计算节点,建立目标库相应的用户,schema,表,按如下指令创建相应对象:
kl@kunlun3:~$ psql -h 192.168.0.155 -p 47001 -U adc postgres
create user test with password 'test';
grant create on database postgres to test ;
exit
kl@kunlun3:~$ psql -h 192.168.0.155 -p 47001 -U test postgres
create schema test ;
create table test.target1 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;
create table test.target2 (pk int primary key, dt datetime(3), txt1 text , txt2 text ,txt3 text ) ;

注意:目标端的数据表必须有主键,才能确保不会重复执行SQL语句,否则新的CDC主节点会把上一个主节点在退出之前最后若干秒之内的所有操作会再次执行一遍,那样就会导致相关数据行被重复地插入、删除或者更新,导致目的端数据与源数据库中的数据不再一致,那样还可能会导致后续数据同步失败和无法继续。
打开XPanel:http:// 192.168.0.152:40180/KunlunXPanel/#/cdc/worker ,为MySQL向Klustron进行数据同步添加CDC任务:

点击“+新增”,输入如下参数:

然后,点击 “shard参数:“右侧的“添加+”,弹出如下对话框:
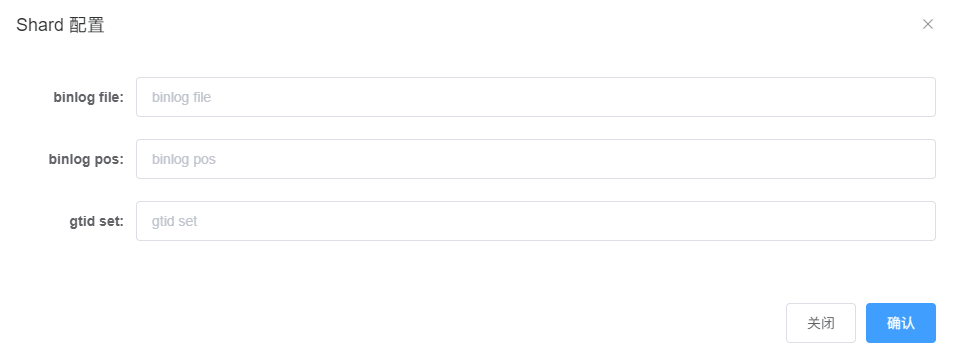
这里,需要连接到MySQL,获取该服务实例当前的这几个参数信息,按如下指令操作:
root@kunlun3:~# mysql -h 127.0.0.1 -P 3306 -u root -p
mysql> show master status ;
输出信息如下所示:

将 file, position, executed_gtid_set 填写至前述shard 配置信息对话框中,如下所示:

点击“确认”保存配置信息,继续进行“输出参数:”配置:

点击“添加+”后,弹出如下对话框:

上述参数录入完成后,点“确认”保存参数配置,配置任务窗口当前显示如下:

再次点击“确认”后,XPanel将会向CDC服务提交一个MySQL到Klustron的同步服务任务,界面示例如下:

如果同步任务的状态正常,则我们可以接下来进行数据同步过程中的高可用测试,包含如下7个步骤:
- 准备目标端(Klustron侧)数据检测程序;
- 准备源端(MySQL侧)数据变更程序;
- 准备好杀除192.168.0.152上CDC进程的指令;
- 启动目标端数据检测程序;
- 启动源端数据变更程序;
- 执行192.168.0.152上的CDC 进程杀除指令;
- 查看目标端检测程序是否正常,确认数据同步的结果
2.1.1 目标端数据检测程序
check_data.py (python2 代码格式)
-------------------------------------------------
import threading
import time
from datetime import datetime
import mysql.connector
config = {
'host': '127.0.0.1',
'port': '47002',
'user': 'test',
'password': 'test',
'database': 'postgres'
}
def check_table(table_name):
connection = mysql.connector.connect(**config)
cursor = connection.cursor()
try:
while True:
query = "SELECT dt FROM %s LIMIT 1" % table_name
cursor.execute(query)
result = cursor.fetchone()
if result:
record_time = result[0]
now = datetime.now()
time_diff = (now - record_time).total_seconds() * 1000.0
print "Table: %s, Time Difference: %d ms" % (table_name, time_diff)
break
else:
time.sleep(0.005)
except mysql.connector.Error as err:
print "Error:", err
finally:
cursor.close()
connection.close()
print "Thread for %s has finished execution" % table_name
thread1 = threading.Thread(target=check_table, args=('target1',))
thread2 = threading.Thread(target=check_table, args=('target2',))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
代码说明:
- 连接到Klustron,启动两个线程,不断轮询各自的表中是否有记录;
- 如有记录,说明CDC同步成功,则拿记录中的时间字段的值与当前时间比对,得出该同步过程花费的时间,打印该同步时长。
2.1.2 源端数据变更程序
run_load.py (python2代码格式)
---------------------------------------------
import threading
import mysql.connector
from datetime import datetime
config = {
'host': '192.168.0.155',
'port': '3306',
'user': 'test',
'password': 'test',
'database': 'test'
}
def insert_data(source_table, target_table):
try:
db_connection = mysql.connector.connect(**config)
cursor = db_connection.cursor()
now = datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')[:-3]
insert_query = "INSERT INTO %s SELECT pk, '%s', txt1, txt2, txt3 FROM %s ;" % (target_table, now, source_table)
cursor.execute(insert_query)
db_connection.commit()
print "Data inserted into %s from %s" % (target_table, source_table)
except mysql.connector.Error as error:
print "Error: %s" % str(error)
finally:
if db_connection.is_connected():
cursor.close()
db_connection.close()
print "MySQL connection is closed for %s" % target_table
thread1 = threading.Thread(target=insert_data, args=('source', 'target1',))
thread2 = threading.Thread(target=insert_data, args=('source', 'target2',))
thread1.start()
thread2.start()
thread1.join()
thread2.join()
root@kunlun3:~#mysql -h 192.168.0.155 -P 3306 -u test -p test
insert into mysql2kl values(1,'aaa');
代码说明:
- 连接到MySQL,启动两个线程,同时以insert into select 方式分别向各自的表(target1,target2)插入5000行记录。
- 为了有足够的时间观察同步过程及同步过程中执行CDC 进程杀除的行为,target1,target2设计了多个宽列,并将单个事务的记录增加到5000行。
2.1.3 准备CDC 进程杀除指令
用ssh连接到192.168.0.152(这是当前CDC工作集群的当前服务机器),在提示符位置输入如下指令:
kl@kunlun1:~$ killall -9 kunlun_cdc
注意:不要回车执行,只是准备好
2.1.4 启动目标端数据检测程序
用ssh开启连接到192.168.0.155的窗口,在机器的提示符下运行如下指令:
root@kunlun3:/home/kl# python2 check_data.py
程序将对klustron中的两个表进行轮询,在查询到同步数据后,会向控制台输出同步时长并退出。
2.1.5 启动源端数据变更程序
用ssh开启连接到192.168.0.155的窗口,在机器的提示符下运行如下指令:
root@kunlun3:/home/kl# python2 ./run_load.py
程序将对MySQL中的两个表分别插入5000条记录,插入完成后,将向控制台输出信息并退出。
2.1.6 执行192.168.0.152上的CDC 进程杀除指令;
在之前已准备好的CDC 进程杀除指令窗口,回车,执行进程清除,如下所示

2.1.7 查看目标端检测程序是否正常,确认数据同步的结果
在执行CDC进程清除任务后,观察python2 ./check_data.py 的输出信息,经过一段时间后,已正常输出同步信息,如下:

源端 python2 ./run_load.data 此时也完成了程序执行,已正常退出,如下所示:

说明:该程序设计为如果在目标表查询不到任何数据,则一直会轮询,不会退出,且不会输出任何信息,所以能看到正常输出,且已经退出,说明同步任务是完全正常结束了。
再打开XPanel,同样我们可以看到,CDC服务界面中,192.168.0.152机器的服务状态为“无效”,当前CDC服务由192.168.0.153接管,如下所示:

以上实验步骤展示了CDC 高可用服务的可用性。
2.2 CDC 并行复制与串行复制的性能对比测试
在上述测试CDC服务高可用的场景中,配置的CDC 任务类型,使用的插件类型是 event_sql,即CDC任务执行时是单线程的,对于源端有多于1个表的数据变更的情况中,CDC任务将顺序完成目标端数据的同步,所以,在前述测试中,我们看到对target1表的同步耗时明显少于target2,我们将再次执行一次无CDC高可用服务中断影响的情况下,两个表同步的时长差异,作为后续对于CDC并行复制的对比数据,先清理目标端的数据,执行如下令:
root@kunlun3:/home/kl# psql -h 192.168.0.155 -p 47001 -U test postgres
postgres=> truncate table test.target1;
postgres=> truncate table test.target2;
再清理源端的数据,执行如下指令:
root@kunlun3:/home/kl# mysql -h 192.168.0.155 -P 3306 -u test -p test
mysql> truncate table target1;
mysql> truncate table target2;
启动目标端数据检测程序
root@kunlun3:/home/kl# python2 check_data.py
启动源端数据变更程序
root@kunlun3:/home/kl# python2 ./run_load.py
稍等一会后,目标端数据检测程序退出,输出如下信息:

从上述数据看到,第一个表(target1)的数据同步完成时间约14秒,第二个表(target2)同步完成时间约为22秒,比第一个慢了差不多8秒。
在下一步配置并行CDC复制之前,我们仍然先清理目标表与源表的数据,执行如下指令:
root@kunlun3:/home/kl# psql -h 192.168.0.155 -p 47001 -U test postgres
postgres=> truncate table test.target1;
postgres=> truncate table test.target2;
postgres=> exit;
root@kunlun3:/home/kl# mysql -h 192.168.0.155 -P 3306 -u test -p test
mysql> truncate table target1;
mysql> truncate table target2;
mysql> exit;
返回到XPanel窗口,删除当前的CDC同步任务,我们将其任务重新配置为并行复制类型(parallel_sql),先点击“删除”按钮,删除当前任务,按如下操作:

按提示信息,输入确认信息,点击“确定”按钮:

任务删除完成:

再次点击“+新增”配置CDC任务:

为控制篇幅,具体的配置过程不再赘述,只是注意如下的配置界面中的参数:

即CDC插件类型选为“parallel_sql”,在完成CDC任务配置后,XPanel上添加了如下数据同步任务:

启动目标端数据检测程序
root@kunlun3:/home/kl# python2 check_data.py
启动源端数据变更程序
root@kunlun3:/home/kl# python2 ./run_load.py
稍等一会后,目标端数据检测程序退出,输出如下信息:

从上述数据看到,第二个表(target2)的数据同步完成,比第一个表(target1)慢了不到1秒,对比之前单线程串行同步两个表的情况下,时间差有8秒左右,这次使用CDC并行复制任务,源到目标的同步性能有非常显著的提升,说明CDC同步任务对于高并发的应用系统,有需要多表数据同步的场景下,应该优先使用CDC并行复制方式。