
InnoDB事务可见性原理及在Klustron(原KunlunBase)中并行查询方案的应用
在2月23日线上直播课程【Klustron Tech Talk】中我们聊 MySQL 事务可见性以及在并行查询中的应用,MySQL 默认和使用最多的存储引擎是 InnoDB,本文以下都以 InnoDB 为例。
一、事务的隔离级别
InnoDB 支持 4 种隔离级别,read uncommitted(未提交读)、read committed(读提交)、repeatable read(可重复读)、Serializable(串行化)。
未提交读是指事务还没提交,但期间所做的更新已经可以被其他事务看见,这个隔离级别下,数据库行为不符合事务原子性特征,很少使用;串行化是指事务未提交前,它访问的行都不能被其他事务访问,这个隔离级别严重影响并发度,也很少使用。
读提交和可重复读是常用的两种隔离级别,Oracle 默认的是读提交,InnoDB 默认的是可重复读,这两个隔离级别下,事务的更新都必须在提交之后,才能对其他事务可见。
可见的时机略有差别,我们用一个对照例子来说明。
我们在 Klustron 库中建了 kunlun_t1 表,表中两个字段(id int primary, c int)。
初始化插入两行(1,1),(2,2)。(如下图)
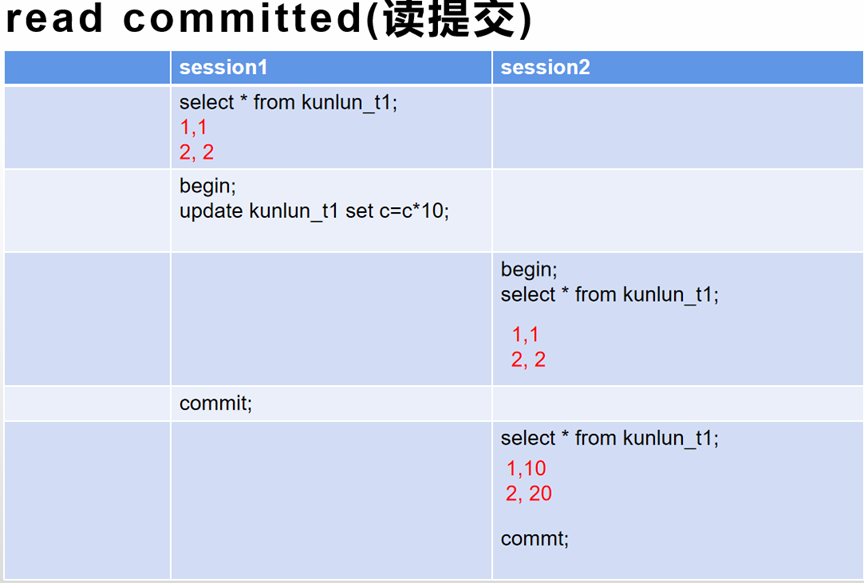
图1 演示案例是在隔离级别为 read-committed 下执行的。可以看到,在 session1 提交(执行commit语句)前,session2 查到的 c 列的值还是 1 和 2。在 commit 语句执行后,session2 再查就返回 update 后的结果 10,20。
这个就是读提交的逻辑:“事务提交后,所做的更新就能被其他事务看见”。
再来看可重复读隔离级别下的对比结果。(如下图)

上图的执行结果区别是,session2 第二次执行 select 语句,看到的两行结果里,c 列的值仍然是 update 语句前的状态,(分别是 1 和 2)。
这个就是可重复读的逻辑:“事务启动后,对数据行重复访问,得到的结果与事务创建时一致”。
Session2 的事务是在第一次执行 select 语句时创建的,因此在这个事务提交前,再次访问这两行,看到的是不变的结果,即使这时 session1的事务已经提交。
这个就是可重复读隔离级别下的事务可见性规则:
本事务做的更新都可见
其他事务未提交的更新都不可见
其他事务T已提交的更新
a) 若T提交后,本事务才启动,可见
b) 否则不可见
用一句话来辅助我们分析可见性,可以这么说:RR 隔离级别下,启动事务后,事务得到一个数据库的一个“静止”的快照。
二、为什么需要可重复读
虽然看上去读提交更符合直观逻辑,实际上可重复读的应用场景也很广泛,因为很多时候我们对数据的逻辑一致性要求更高,比如全库备份,就需要用到可重复读隔离级别下的这个特性。
假设我们的库里有 a,b 两张表,事务 T 执行 update a, b set a.c=100 and b.c=1000 where a.id=1 and b.id=1,并成功更新了两个表里各一行。
设想一个全库备份的场景,如下图是一种可能的操作时序。

对于备份逻辑来说,事务 T 必须是一个原子操作。也就是备份的结果里,要么都是修改之前的值,要么都是修改后的。
但在读提交隔离级别下,上面的操作顺序,备份的结果里,a 表 id=1 的行是事务执行后的,而 b 表 id=1 的 c 的值是 1000,备份出来了“事务的中间状态”。
因此做备份时,都需要将备份 session 里显式地设置成可重复度隔离级别,在各种版本的 mysqldum 工具里,都能从源码里找到这个语句。
三、可重复读是怎么实现的
我们上面说,InnoDB 可重复读的实现,是在事务启动时,给整库“拍了个快照”。但显然不能通过拷贝一份全库数据来实现,那样成本就太高了。
InnoDB 是通过多版本并发控制来实现的。每份数据有可能有多个版本,每次更新时,并不是简单的原地覆盖,而是增加了一个新的版本,每个版本记录了“生成这个版本的事务号”。
在查询时,给每个事务分配了一个可见性视图(read-view),这个 read-view 用来跟数据上的版本事务号做对比,来判断数据的多个版本里,哪个版本是对这个查询事务可见的。
这一部分的逻辑比较复杂,我们在系列【Klustron Tech Talk】的后续中展开。
四、HTAP 和并行查询
本篇接下来的部分要讨论的是 InnoDB 事务隔离对并行查询方案的影响。
并行查询是 HTAP 的关键技术之一,也是 HTAP 数据库的必备的能力。
基于不同的应用架构,并行查询的方案也有所不同。
Klustron 是典型的计算层 + 存储层的架构(如下图)。
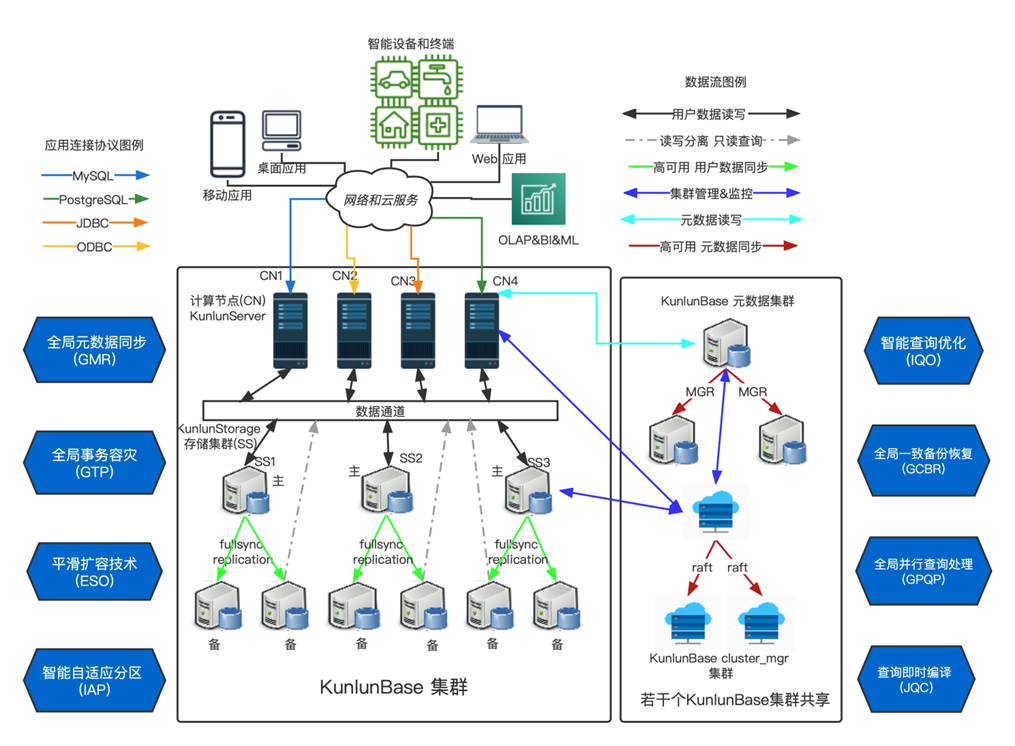
实现并行查询的方式,是在计算节点(图中的 CN)优化器将用户输入的 SQL 语句得到解析树后,拆分成可并行执行的多个子查询,并构造出对应的子查询语句,下发到存储节点(图中的 SS)。
虽然下发到存储节点是多个语句,但是从业务逻辑来说,还是同一个查询事务。
Klustron 的存储节点是基于 MySQL 的。我们前面说到,MySQL 每个事务的可见性是独立的,因此在实现上,我们需要让多个子查询共享同一个数据库快照。(如下图)

Klustron 通过 read-vew 复制,实现了跨线程共享一致性视图,这样就可以确保多个并行执行的子查询看到的数据满足一致性的要求。
五、Q&A 部分
昨天直播最后的 Q&A 环节收到几个质量很高的问题,这里也记录一下。
Q:能否介绍下数据库选型,基于 PG 还是 MySQL?
A:MySQL 在中国更流行的一个原因是资料多,如果用于 kv 和简单的二维表关系维护的,选择 MySQL 的多一些,除了 InnoDB 外,RocksDB、TokuDB、Spider 等引擎也有特定的应用场景。
在需要一些特殊功能时,可以考虑选择有功能上有优势的产品。比如 PG 的 GIS 能力就比 MySQL 的 GIS 能力强很多。
还有我们本篇提到的并行查询,MySQL 的官方版到 8.0 还没有支持,而 PG 则是很早就提供了这类优化。
Klustron 的计算层是基于 PG 的,我们在做进一步的并行查询优化时也是充分利用了原有的能力。
Q: for update 语句能不能使用并行查询?
A:在我们现在实现的版本里是不行的,因为并行查询的多个子查询里,除了第一个以外,其他都必须通过 “start transaction read only from session XX” 启动一个只读事务来实现,这样就跟 for update 的逻辑冲突了。
注:这里在直播当时回答时有误,此处勘误。
Q:使用多个子查询,会不会出现子查询的优化器结果不同的情况?
A:Klustron 的优化器阶段是在计算节点做的,之后拆成多个子查询分发到存储节点计算。因此在存储节点执行的基本都是简单语句(简单的范围查询和排序等),因此不太可能出现子查询优化器结果不同的情况。
退一步说,即使优化器结果不一致,也只是影响执行过程,查询结果是一样的。
Q: 使用并行查询功能需要指定特殊语法吗?还是说它可以直接透明启用的?
A: Klustron 的并行查询是默认启用的,语句不需要特殊处理。
同时,由于 AP 查询的成本往往较高,可以配合 Klustron 的读写分离来使用。
使用 “set enable_repliaca_read = true; ”命令之后再执行查询语句,会将子查询优先发给只读节点。