
Klustron对比社区版PostgreSQL之PostGIS性能及扩展性测试
Klustron对比社区版PostgreSQL之PostGIS性能及扩展性测试
Klustron数据库是存算分离的分布式架构,相比于普通的社区版PostgrSQL数据库,拥有更好的弹性计算性能和扩展性,本文通过使用网上公开的纽约出租车数据,将其分别装载到Klustron环境和社区版PostgreSQL环境,运行一些典型的分析型SQL,获得性能对比结论。
另外,由于Klustron本身的架构支持计算性能的水平扩展,所以,在业务需要时,可以灵活方便的水平扩展计算能力和存储容量,相比于社区版PostgreSQL只能单体垂直扩充单机的做法,在整体吞吐能力和存储容量上有绝对的优势。
PostGIS是PostgreSQL社区最知名的功能扩展之一,其历史和知名度与PostgreSQL相当,在GIS数据管理领域基本上是最广泛使用的事实标准。
泽拓昆仑Klustron从1.3版本开始,支持了PostGIS扩展,用户可以用与挂载PostGIS到PostgreSQL完全相同的方法,把PostGIS挂载到Klustron的计算节点,来使用PostGIS的所有功能。这就让Klustron成为了一个分布式的PostGIS数据库,这极大地放大了PostGIS的GIS数据管理和计算能力,特别是考虑到GIS数据的计算(空间位置关系判别,以及空间对象的计算和生成)的计算量远远大于数值、字符串等简单数据类型,如果使用PostgreSQL挂载PostGIS的话,单台服务器的计算资源很容易成为严重的性能瓶颈。而Klustron分布式数据库可以使用上不封顶的计算资源,只要按需增加计算机服务器机器(这是最简单也是最低成本的操作)即可。
在实现层面,我们基于PostGIS-3.3.4,对其GIS数据存储读写略做修改,以便可以把GIS数据存储到Klustron的存储节点中。同时,我们做了大量细致的开发工作以便让PostGIS的空间计算函数可以下推到存储节点执行,以便通过并行化提升GIS查询性能,并且避免无用数据在计算节点和存储节点之间传递。
MySQL-8.0支持GIS数据存储和计算,并且自从MySQL-5.7开始,Oracle MySQL团队就重写了其GIS实现,使用boost.geometry作为GIS计算内核,在性能和准确性方面实现巨大提升。特别是MySQL-8.0支持了与PostGIS几乎完全相同的坐标系集合,因而广泛适用于全球各地的用户,他们可以使用本地坐标系系统,与使用PostGIS完全相同。所以,Klustron的PostGIS插件,在功能方面完全与PostgreSQL+PostGIS相同,在性能和可扩展性方面大大优于后者。
如下文所示,我们的实测表明,泽拓昆仑Klustron的PostGIS 在功能层面完全兼容PostGIS,而且性能也优于单机PostgreSQL挂载PostGIS的性能。
本文通过使用网上公开的纽约出租车数据,将其分别装载到Klustron环境和社区版PostgreSQL环境,运行一些典型的分析型SQL,获得性能对比结论。
01 测试环境
测试环境一: (Klustron)
| 节点类型 | IP | 端口 |
|---|---|---|
| 计算节点 | 192.168.0.19 | 47001 |
| Shard1主节点 | 192.168.0.21 | 57007 |
| Shard2主节点 | 192.168.0.19 | 57003 |
| Shard3主节点 | 192.168.0.20 | 57005 |
| XPanel | 192.168.0.19 | 40180 |
运行环境,3台测试服务器配置相同:CentOS 8.5 Linux 64位,AMD Ryzen 9 7950X 16-Core(32线程), MEM: 128G, 存储:SSD 2T(M.2 SSD PCIE 4 固态)
PostGIS: 3.3.4
测试环境一: (PostgreSQL 11)
| 节点类型 | IP | 端口 |
|---|---|---|
| 单机 | 192.168.0.21 | 5432 |
运行环境:CentOS 8.5 Linux 64位,AMD Ryzen 9 7950X 16-Core(32线程), MEM: 128G, 存储:SSD 2T(M.2 SSD PCIE 4 固态)
PostGIS: 3.3.5
02 性能对比
2.1 测试环境调优
为了确保测试过程中能发挥机器的资源配置性能及提升测试结果,我们在Klustron和PostgreSQL初始安装完成后,都对相关的参数做了适当的调整,如下所示:
Klustron:
计算节点:
shared_buffers='32GB';
statement_timeout=600000000;
mysql_read_timeout=360000;
mysql_write_timeout=360000;
mysql_interactive_timeout=360000;
mysql_connect_timeout=100000;
mysql_wait_timeout=360000;
lock_timeout=360000000;
log_min_duration_statement=120000000;
effective_cache_size = '8GB';
work_mem = '1GB';
wal_buffers='64MB';
autovacuum=false;
metadata_connect_timeout=100000 ;
metadata_read_timeout=100000 ;
metadata_write_timeout=100000 ;
存储节点:
innodb_buffer_pool_size=32*1024*1024*1024;
lock_wait_timeout=3600;
innodb_lock_wait_timeout=3600;
fullsync_timeout=1200000;
enable_fullsync=false;
innodb_flush_log_at_trx_commit=0;
sync_binlog=0;
max_binlog_size=1*1024*1024*1024;
net_read_timeout=3600 ;
net_write_timeout=3600 ;
thread_pool_queue_congest_req_timeout=3600 ;
rocksdb_lock_wait_timeout=3600 ;
delayed_insert_timeout=3600 ;
connect_timeout=3600 ;
delayed_insert_timeout=3600 ;
innodb_lock_wait_timeout=3600 ;
mysqlx_connect_timeout=3600 ;
mysqlx_read_timeout=3600 ;
mysqlx_write_timeout=3600 ;
mysqlx_wait_timeout=3600 ;
说明:因测试条件有限,存储节点3个分片的备节点都与主节点共享了同样的机器,为消除资源争用的影响,3台测试机器上的存储备节点都已通过XPanel操作,实施了禁用。
PostgreSQL:
shared_buffers='32GB';
statement_timeout=600000000;
lock_timeout=360000000;
log_min_duration_statement=120000000;
effective_cache_size = '8GB';
work_mem = '1GB';
wal_buffers='64MB';
autovacuum=false;
2.2 测试数据准备:(NYC Taxi Data)
访问:https://github.com/toddwschneider/nyc-taxi-data/tree/master 此链接包含了纽约出租车数据的数据装载入库脚本,同时,脚本中也包含了数据下载的链接,按README的说明,对Klustron和PostgreSQL装载同等数量的数据(数据区间:2019-01至 2022-11),为测试做准备,数据准备情况如下:
Klustron:
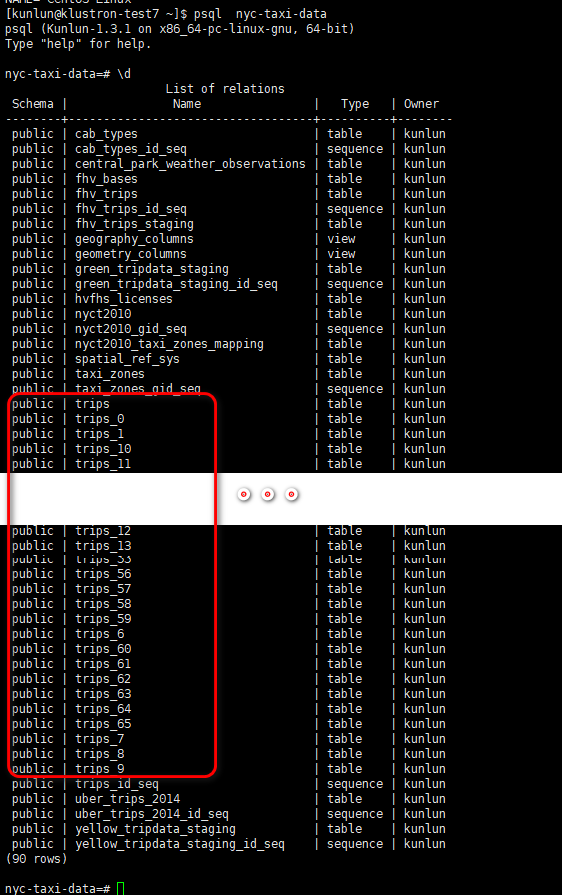
因为Klustron存储有3个分片,故对trips表设计了64个分片,分区表的名字从trips_0至trips_65,数据均匀的分布在3个分片存储的64个分区中,总记录数为1.7亿多行,如下:

PostgreSQL:
因为该数据库为单机环境,故trips表不再设计分区,直接单表装载,数据情况如下:
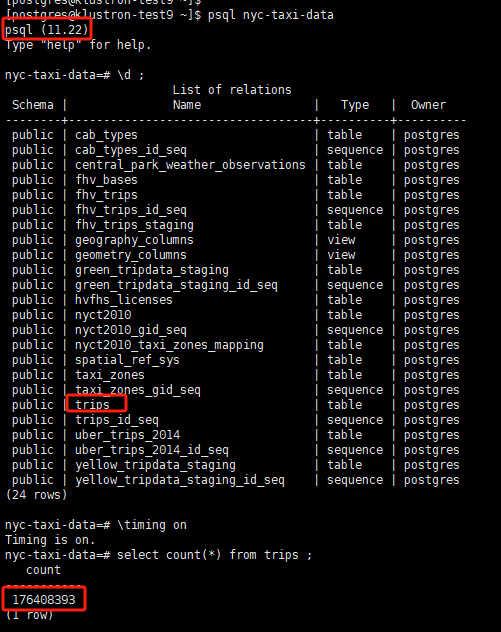
备注:在测试之前,对两个环境中的trips表和及相关的分区已做分析,生成统计信息,确保优化器会生成最优的执行计划。
2.3 性能测试对比
Q1: SELECT cab_type_id, count(*) FROM trips GROUP BY cab_type_id;
Q2: SELECT passenger_count, avg(total_amount) FROM trips GROUP BY passenger_count;
Q3: SELECT passenger_count, to_char(pickup_datetime,'yyyy-mm') AS month, count(*) FROM trips GROUP BY passenger_count, month;
Q4: SELECT passenger_count, to_char(pickup_datetime,'yyyy-mm') AS month, round(trip_distance) AS distance, count(*) FROM trips GROUP BY passenger_count, month, distance ORDER BY month, count(*) DESC;
测试结果:
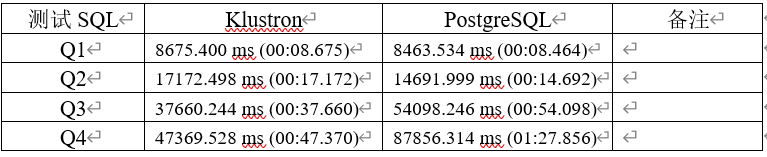
从上述测试结果可以看观察到,在初始简单的SQL测试中,Klustron与PostgreSQL并没有太大的性能差异,但随着SQL 复杂度的提升,Klustron分布式架构的性能明显发挥了作用,与社区版PostgreSQL拉开了明显的差距,可以推断,随着数据量的进一步上升和SQL复杂度的提升,Klustron将发挥比社区版PostgreSQL能存更多数据,跑得更快的优势。