
HTAP数据库能力系列分享:读写分离
HTAP数据库能力系列分享:读写分离
本期金句:
因为有了读写分离能力,Klustron 才可以做到 OLTP 和 OLAP 负载完全分离,避免资源争用,互不影响性能。
01 为什么需要读写分离?
在数据库具备水平扩展能力后,应对单机压力过大,一般有两种思路,一个是分片,一个是读写分离。
水平分片是把数据按照一定规则分散到多组数据库实例中,应用访问数据时根据规则路由到对应分片。
读写分离则是在一主 N 从架构中,让从库承担部分业务读请求。
这两种方案各有优势,分片后,每个分片可以独立读写,系统的写入能力也有提升;只访问每个分片的主库,也不需要考虑主从延迟的问题。
分片方案的劣势在于由于数据被分到多个分片主库中,一些数据访问逻辑会变复杂,比如一些跨表 join 语句。还有读写分离方案扩容时只需要增加备库,不需要更改主库数据,成本更低。
尤其在类 AWS aurora 的计算存储分离方案中,新增从库的代价非常小,这两个方案实施代价的差距就更明显。
读写分离方案需要考虑备库延迟,因此需要业务清楚哪些语句可以使用读写分离策略,在 HTAP 场景下,分析型需求的语句大多数是可以接受这种秒级延迟的,又会占用较多计算资源,因此读写分离功能可以说是 HTAP 数据库必备的。
读写分离方案至少要做到对业务代码透明。对于没有中间层,也就是业务层直连数据库的架构,常见的方案是用类似 zookeeper 的第三方服务维护主备信息,再由客户端的连接框架负责实现读写分离的逻辑。对于有中间层的的架构,成熟的中间层会内置读写分离能力,这样业务端就可以用普通的客户端直接访问。在云环境下,第二种方案应用会更广泛。
Klustron 是通过计算层路由请求给存储层的,架构图如下:
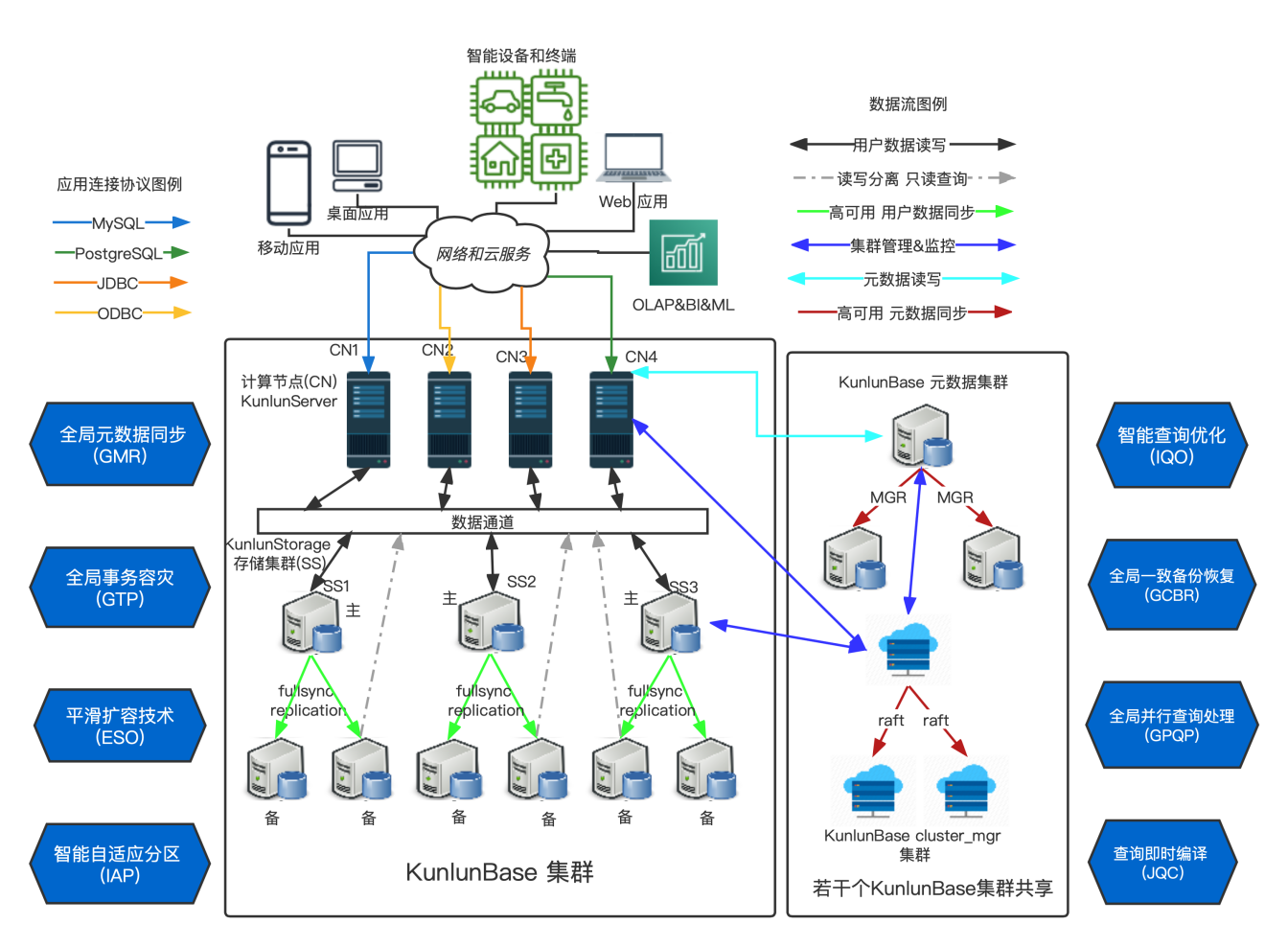
客户端可以通过 set enable_replica_read=on;开启读写分离功能。
02 读写分离实现中的问题关注
2.1 从库的选择策略
在有多个从库的时候,需要考虑选择哪个从库,一般的策略是选延迟最小的从库,当然如果从库有配置或负载的差异,也会给从库配置不同的权重,在延迟都满足需求的情况下按照权重选择。
读写分离原则上是写访问主库,读访问从库。但并不是所有的读请求都可以走从库,比如一个显式事务中,先更新了数据行,之后在做的查询就只能继续访问主库,因为此时事务还没有提交,binlog 还没有生成,从库是一定看不到这个更新的,只有继续访问主库,才符合事务隔离的特性。
Klustron 的读写分离策略是,当用户的 SQL 同时满足如下条件:
- 当前 SQL 类型为 select;
- SQL 中不包含用户自定义函数(即 create function 语句创建的函数),除非当前事务为只读事务;
- 如果不在事务中( autocommit=on ),则允许读写分离;如果语句在显示事务中,则要满足:
a)如果在只读事务中,则允许读写分离;
b)如果在读写事务中,则该事务尚未更新过任何数据;
远程查询优化器就会将相应的 SQL 执行计划下发到备机的节点上执行。
2.2 主备延迟
了解了数据库读写分离实现的注意事项,就不难想到,在使用时也要考虑这个点:由于主备延迟的存在,路由到从库的读查询,并不能保证拿到的是最新的数据。
这个延迟是无法避免的,基于 MySQL 基于 binlog 的同步策略有异步复制、半同步复制、fullsync(by Klustron)、事务强一致同步。
其中事务强一致同步是指事务在从库应用完 binlog 反馈给主库,主库再返回事务提交成功的信息给客户端,这个在性能和可用性上牺牲太大,生产上很少使用。
另外的三种同步机制,主库 ack 给客户端的时候,都无法保证事务已经在从从库上回放完成。
因此使用读写分离前,业务要能知道并接受这个延迟的存在。
如果无法接受的,只能全走主库,根据上面提到的规则,使用 Klustron 读写分离集群,有两种方式强制走主库,一种是在线程里执行set enable_replica_read=off;关掉读写分离策略,一种是发一个带写或者写锁的 SQL 语句,之后这个事务的所有查询语句就都只会访问主库。
2.3 一致性读的“bug”
在读写分离的机制实现里,还有一个容易被忽略的一致性读的 “bug”,我们来深入分析一下。
先回顾可重复读(repeatable-read)隔离级别的机制。
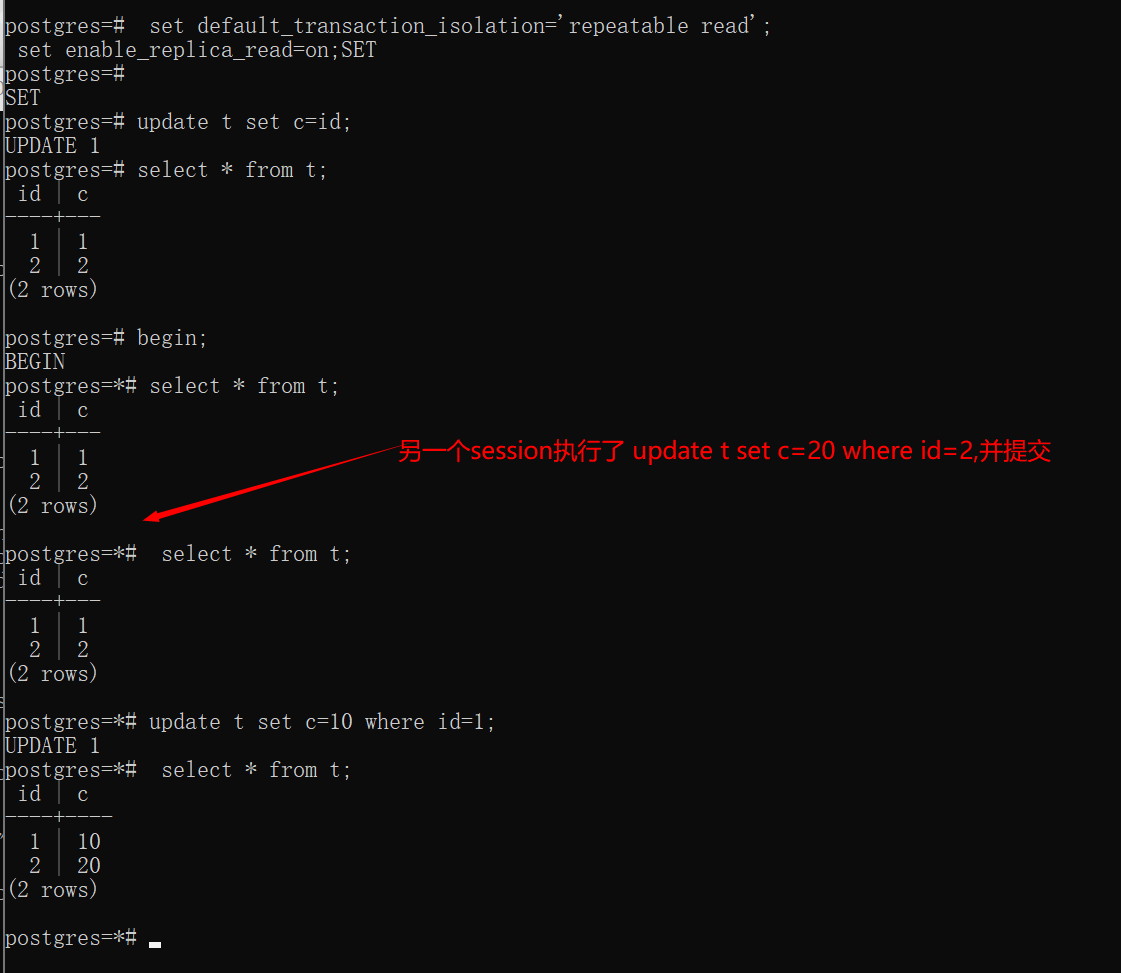
库中有一个 InnoDB 表,有两列(id, c),id 列为主键,只有两行数据,初始值分别为(1,1), (2,2)。如下图:

假设我们在没有读写分离机制下作以下的操作序列(在 session1 开头语句加入set enable_replica_read=off;)使这个连接接下来的请求都不走读写分离策略,也就是都只走主库;
在 session1 的第三次 select 语句中,看到的第二行的 c 值为 2, 因为这个事务创建时机是在 sessoin2 的 update 语句之前的,因此看到的 id=2 这一行的版本就是(2,2)。这个是符合可重复读隔离级别行为的。
我们再打开读写分离策略执行这个操作序列,可以看到 session1 的第三次执行看到的结果不同了,看到的 id=2 这一行的 c 值是 20。如下图:

原因就是启用读写分离后,session1 这个事务一开始的事务视图是在从库上创建的,当执行到第一个 update 语句时,主库上的事务视图才创建,这时候创建的事务视图里,session2 已经更新提交过了,因此能看到这个值被改成了 20。
这个问题是否严重取决于业务对可重复读隔离级别的需求,需要业务来评估。我们在直播最后把这个问题的改进方案留作后续讨论。
03 Q&A 讨论
问题讨论Q:
开启读写分离后,这个行为与 repeatable-read 的行为有不一致,如何解决?
直播A:
可以在从库的事务开启时,在主库也创建一个事务视图,等于时空事务,这样可以解决这个可重复读的问题。
交流群(@阿咘)A:
问题的关键是想办法通过 readview 或者类似的机制把另外一个事务新写入的行过滤出来,其实和分布式数据库的跨节点一致性读问题很像,有 3 个方案:
- 存储节点的 MySQL 使用 binlog 复制的情况下,在行上面加 1 个隐藏列,里面存事务号,为了保证这个时间戳在各个节点(当然也包括主备节点)一致,可能是一个类似全局单调递增类似逻辑事物号的东西,读写事务和只读事务开启都需要获得全局事务号,写事务结束时要获取全局事物号,写事务提交时要把提交事务号写到这个隐藏列上面,事务提交时在修改的行上面写这个事务号是需要代价的,读事务要用事务开启时拿到的事务号和行的事务提交的事务号做对比来判断这个行是否可见,提交事务号小于读事务开启的事务号时该行可见。当上面的图 select 做完后做 update 会从只读事务切换成读写事务时,会在主库发起一个新事务,这时拿着备库只读事务开启时拿的事务号去主库上面发起一个新的事务,因为事务号是备库生成的,所以备库读不到的数据主库也读不到。
- 如果存储节点主备能用 redo 做复制,主库在 redo 中记录事务的开始和结束,备库就能构造活跃事务链表,备库就能接受读请求且支持 mvcc。因为主备的事务号由redo保证一致,那么可以直接把备库读事务的 readview 关联到主库发起的读写事务上面去,这样主库能读到的数据就是备库readview应该读到的数据加上主库自己的事务id写的数据,就不会读到别人写的数据
- 如果存储节点主备用 redo 复制,备库能接受读请求,是可以实现一个读写求全部发给主,读请求全部发给备的。图中做完 update 后的 select 仍然发给备库,只不过这个时候备库的 readview 里面要知道主库与备库读事务相关联的写事务的事务 id,这样只要备库 apply redo 的 LSN 超过主库 update 完的 LSN,备库就能读到主库写事务的数据,其他事务写的行由于受到 readview 过滤所以不会被读到。
丁奇老师(回复@阿咘)A:
阿咘同学这个回复里,有一个满足预期的答案、一个超过预期的答案和一个远超预期的方案,赞这些思路。
- 这个是全局事务 id 思路,这个 id 可以写在 binlog 里,也可以由全局事务管理器来生成。这个方案还能支持在多个读节点共同完成读写分离。
- redo log 复制这个是 aurora 的精髓了,这个方案跟 Klustron 已经实现了的线程间共享 readview 的功能,有异曲同工的感觉。
- 这个是真·读写分离的完全体了,希望以后的硬件能力能把延迟降到这个方案不影响性能的程度。
交流群(@阿咘)A:
谢谢丁奇老师的指点,说是一回事,想要工程实现的话还是有很多细节需要考虑的,最终可能会做很多权衡的考虑,能最终实现和落地到业务才是真的厉害,期待昆仑数据库以后的新功能新特性
赵伟老师(回复@阿咘)A:
我们会在 Klustron 的全局 mvcc 功能里面加入对读写分离的查询结果一致性的支持,不过技术路径与 @阿咘 说的办法不太一样,当然确实涉及到对 Binlog 系统和 InnoDB 的大量内核修改。等1.2版本发布后我们会详细介绍。
04 小结一下
读写分离是一种将数据库的读操作和写操作分离到不同的服务器上进行处理的技术,可以提高数据库系统的性能和可用性。通过将读操作分配到从服务器上,可以减轻主服务器的负担,提高数据库系统的性能和吞吐量。
当 HTAP 技术与读写分离结合使用时,可以实现更高效、更快速、更经济的数据库处理解决方案。将 HTAP 技术应用到读写分离架构中,可以实现实时的事务处理和复杂分析处理的需求,并通过读写分离技术提高数据库的性能和可用性。