
分布式事务处理两阶段提交机制和原理
分布式事务处理两阶段提交机制和原理
一、背景
Klustron 的分布式事务处理机制基于经典的两阶段提交算法,并在此基础上增强了其容灾能力和错误处理能力,解决了经典的两阶段提交算法的缺陷 任意时刻 Klustron 集群发生节点宕机或者网络故障、拥塞等都不会导致集群中存储管理的数据发生不一致或者丢失或者导致集群停止服务。
二、Klustron 如何分布式事务处理两阶段提交?
Klustron 分布式事务处理功能涉及的模块分布在计算节点,存储集群和元数据集群和 cluster_mgr集群。
2.1 计算节点模块
计算节点包含全局事务管理器(Global Transaction Manager,GTM),它掌握着一个计算节点中正在运行的每一个客户端连接(即Session,会话)中正在执行的分布式事务 GT 的内部状态,关键信息包括事务 GT 读写了哪些存储集群(storage shard),以及全局事务 ID 等。
下图(如图1)中的 GT1,GT2 内部状态为:
GT1 在存储集群1上执行的事务分支 T11 做了读写操作,在存储集群 2 上执行的事务分支 T12 做了写入操作。
GT2 在存储集群1上执行的事务分支 T21 做了只读操作,在存储集群 2 上执行的事务分支 T22 做了写入操作。
计算节点的 GTSS 后台进程负责成组批量写入全局事务的 commit log 日志到元数据集群中。
Klustron 会确保每一个记录了 Commit log 的全局事务 GT,都一定会完成提交。具体的两阶段提交流程见下文详述,本节先把相关模块介绍完。
2.2 元数据集群模块
元数据集群也是一个高可用的 MySQL 集群,它的 commit log 记录着每一个两阶段提交的事务的提交决定。
这些提交决定是给 cluster_mgr 做错误处理使用的,实际生产系统场景下极少会真的用到,但是其信息非常关键。
只有当计算节点或者存储节点发生宕机、断电等故障和问题时,才会被cluster_mgr用来处理残留的prepared状态的事务分支。
2.3 存储集群模块
存储集群是一个 MySQL 在存储集群中,mysql 的会话(THD)对象内部,包含分布式事务分支(简称 XA 事务)的状态:
在下图(如图1)中存储节点 1 包含分布式事务 GT1 的事务分支 GT1.T11 和 GT2 的事务分支 GT2.T21 的本地执行状态。
在下图(如图1)中存储节点 2 包含分布式事务 GT1 的事务分支 GT1.T12 和 GT2 的事务分支 GT2.T22 的本地执行状态。
2.4 cluster_mgr模块
cluster_mg r是一个独立进程,借助元数据集群中的元数据,与存储集群和计算节点交互,辅助它们工作。
在分布式事务处理这个场景下,它负责处理因为计算节点和/或存储节点宕机而残留的 prepared 状态的事务分支,根据每个事务分支所属的全局事务的 commit log 来决定提交或者回滚其事务分支,如图所示:(具体会在下文详述)。 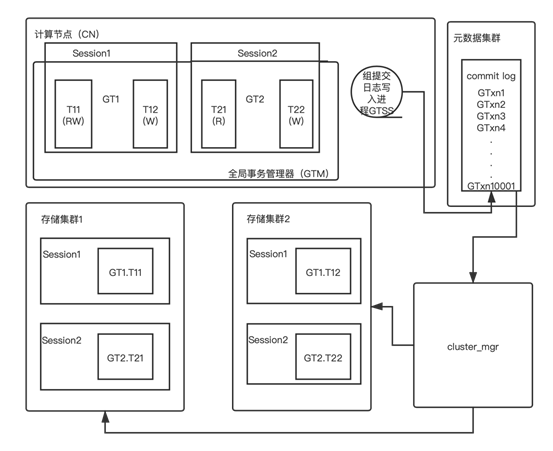
三、如何实现两阶段提交?
在用户发送 begin transaction 给计算节点时,计算节点会在其内部开启一个新的分布式事务 GT 对象(GTM 会为这个分布式事务 GT 建立内部状态)。
然后在 GT 事务运行期间首次读写一个存储集群时,GTM 会发送包含 XA START 在内的若干条 SQL 语句启动 GT 在这个存储集群中的事务分支,并初始化事务状态。
然后发送 DML 语句来读写数据。计算节点会对收到的 SQL 语句做解析、优化、执行并计算应该向哪些目标分片发送什么样的 SQL 语句完成局部数据读写工作,只读写确实含有目标数据的存储集群。
计算节点与一组存储节点的通信总是做异步通信,确保存储节点并发执行 SQL 语句(不过这部分内容不是本文讨论的重点)。
在一个分布式事务 GT 执行 commit 之前如果发生了 Klustron 集群中的节点、网络故障或者存储节点的部分SQL语句执行出错,那么计算节点的 GTM 会回滚事务 GT 及其在存储节点上的所有事务分支,GT 相当于没有被执行过,它不会对用户数据造成任何影响。
下面详述计算节点执行客户端发送 commit 的语句的分布式事务提交流程。事务提交的正常情况流程(时序图)见下图。 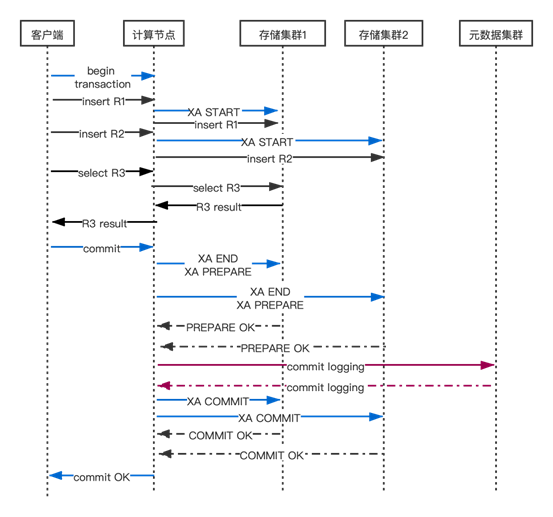
3.1 第一阶段
当客户端/应用发送 commit 语句时,GTM 根据分布式事务 GT 的内部状态选择提交策略(当 GT 写入的存储集群少于 2 个时,对 GT 访问过的所有存储集群执行一阶段提交)。
在 MySQL 中这个 SQL 语句是 XA COMMIT ... ONE PHASE;在分布式事务做第一阶段提交过程中如果发生任意节点宕机,那么这些节点本地完成恢复即可正常工作,用户数据不会错乱、不一致。
具体来说,如果宕机的节点包含那个唯一做过写入的节点 WN,那么 WN 完成本地恢复后,如果 GT 在 WN 的事务分支TX被恢复了,那么 GT 的全部改动(全部在 TX 中)就是生效的,否则 GT 的全部改动(全部在 TX 中)就没有生效(无论如何 GT 的原子性都是保持的)。
如果宕机的节点全部都是 GT 的只读节点那么 GT 的任何改动都没有丢失,也不会造成 GT 的状态出错或者数据不一致。
执行只读事务分支的存储节点重启并完成恢复后,那些之前运行中的只读事务残留的 undo log 都会被 InnoDB 自动清除,其他之前运行时的内部状态全部在内存中,随着重启已经都消失了,因此完全可以忽略只读事务一阶段提交的任何错误。
所以这种情况下,对其唯一的写入节点的 commit 语句可以正常继续执行。
当 GT 写入的存储集群不少于 2 个时,GTM 对 GT 写入过的所有存储集群执行两阶段提交,并且对 GT 只读访问过的每个存储集群执行一阶段提交。
执行两阶段提交时,第一阶段全部返回成功后才会执行第二阶段的提交(XA COMMIT) 命令,否则第二阶段会执行XA ROLLBACK命令回滚所有两阶段提交的事务分支。
3.2 如何批量写 Commit log?
在开始第二阶段提交之前,GTM 会请求 GTSS 进程为每个 GT 写入 commit log 并且等待其成功返回。
只有成功为 GT 写入 commit log 后 GTM 才会对 GT 开始第二阶段提交,否则直接回滚这些 prepared 状态的事务分支。
GTM 在每个后端进程(backend process 是 PostgreSQ L术语,也就是执行一个用户连接中的 SQL 语句的进程,每个用户连接绑定一个后端进程)中会把每个要开始第二阶段提交的分布式事务的 ID 等关键信息放入 GTSS 的请求队列然后等待 GTSS 通知请求完成。
GTSS 会把请求队列中所有的 commit log 写入请求转换为一条 SQL insert 语句发给元数据集群,该集群执行 insert 语句完成 commit logging 并向 GTSS 确认成功,然后 GTSS 即可通知每一个等待着的后端进程开始第二阶段提交。
如果 commit log 写入失败那么计算节点会发送回滚命令(XA ROLLBACK) 让存储集群回滚 GT 的事务分支。
如果 commit log 写入超时那么计算节点会断开与存储集群的连接以便让 cluster_mgr 事后处理。
所有确认写入 commit log 的分布式事务一定会完成提交,如果发生计算节点或者存储节点故障或者网络断连等,那么 cluster_mgr 模块会按照 commit log 的指令来处理这些 prepared 状态的事务分支。
3.3 元数据节点会不会成为性能瓶颈?
一定会有读者担心,把所有计算节点发起的分布式事务的 commit log 写到同一个元数据集群中,那么元数据集群会不会成为性能瓶颈?会不会出现单点依赖?
经过验证并与我们的预期相符的是:在 100 万 TPS 的极高吞吐率情况下,元数据集群也完全不会成为性能瓶颈。
具体来说,在 1000 个连接的 sysbench 测试满负荷运行时,GTSS 批量写入 commit log 的这个组的规模通常在 200 左右,其他的工作负载以及相关参数配置(默认 cluster_commitlog_group_size = 8 和 cluster_commitlog_delay_ms=10)下,这个规模可能更大或者更小。
考虑到每行 commit log 数据量不到 20 个字节(是与工作负载无关的固定长度),也就是 200 个存储集群的分布式事务会导致元数据集群执行一个写入约 4KB WAL日志的事务,那么即使集群整体 TPS 达到 100 万每秒,元数据集群也只有 5 千TPS,每秒写入 20MB WAL 日志,对于现在的 SSD 存储设备来说是九牛一毛,完全可以负担的。
所以即使存储集群满负荷运行,元数据集群的写入负载仍然极低(元数据集群不会成为 Klustron 集群的性能瓶颈)。
GTSS 会最多等待 cluster_commitlog_delay_ms 毫秒以便收集至少 cluster_commitlog_group_size 个事务批量发送给元数据集群。
通过调整这两个参数可以在 commit log 组规模和事务提交延时之间取得平衡。
3.4 第二阶段
当 commit log 写入成功后,GTSS 进程会通知所有等待其 commit log 写入结果的用户会话(连接)进程,这些进程就可以开始第二阶段提交了。
第二阶段中,GTM 向当前分布式事务 GT 写入过的每个存储节点并行异步发送提交(XA COMMIT)命令,然后等待这些节点返回结果。
无论结果如何(断连,存储节点故障),GTM 都将返回成功给用户。因为第二阶段开始执行就意味着这个事务一定会完成提交。
甚至如果第二阶段进行过程中计算节点宕机或者断网了那么这个事务仍将提交,此时应用系统后端(也就是数据库的客户端)会发现自己的commit语句没有返回直到数据库连接超时(通常应用层也会让终端用户连接超时)或者返回了断连错误。
四、总结
本文介绍了 Klustron 的分布式事务两阶段提交算法的基本流程,再加上此算法的故障和错误处理机制,Klustron可以做到任意时刻 集群的任意节点宕机或者网络故障、拥塞、超时等都不会导致集群管理的数据发生不一致或者丢失或者集群停止服务。