
昆仑参天数据库内核关键技术
昆仑参天数据库内核关键技术
引言
昆仑参天数据库是泽拓科技基于华为参天引擎研发的新型集中式数据库产品。作为泽拓科技和华为存储强强联手推出的新产品,它结合了昆仑数据库强大的计算层性能和参天引擎出色的存储处理能力,实现了多场景下数据库功能,性能和稳定性三方面的极大提升。本次分享将主要介绍这款新产品中的一些关键内核技术,已经后续将在此基础上研发的新特性,期望能让大家在对于昆仑参天数据库这款新产品有初步认识的同时,也对其中的内核新技术有一个更为深入了解。
本文金句:昆仑参天数据库结合了昆仑数据库强大的计算层性能和参天引擎出色的存储处理能力,实现了多场景下数据库功能,性能和稳定性三方面的极大提升。
昆仑参天数据库的背景
首先,我们看看我们在使用常用数据库,比如MySQL,来做高可用的时候,经常会碰到的问题。
通常我们在使用MySQL时会用到基于Binlog的主从复制架构来做高可用,这种架构下,通常会碰到如下问题:
主节点事务组提交的性能瓶颈。
- 所有同时并发提交的事务的线程阻塞;
- 由一个线程依次append每个事务的私有缓存中已写好的Binlog事件到Binlog文件;
- 实测表明:如果关掉Binlog,性能可以翻倍。
主备延迟:使得主节点宕机后无主可用。
- 典型成因:表无主键和唯一索引,后来hash机制略改进;
- 典型成因:同一个事务中大批量插入、更新、删除;
- 典型成因:主节点上并发度不够且备机后期加入;大事务(2次IO,写完才发)。
恢复时耗大:存储引擎恢复,然后MySQL server层Binlog recovery
- scan最后一个Binlog文件,可能很大。

而如果我们采用MySQL MGR或Galera来做高可用,又可能碰到集群多写冲突检测开销过大的问题,具体就是:
表必须有主键或者唯一索引,用于hash后作为id来标识行;
事务运行期间收集增删改的行id的集合;
事务提交前先发送增删改的id集合到其他节点,并且检查冲突;
- 如有并发提交的冲突事务,则回滚事务,浪费计算开销。
- 无冲突则 通过raft协议分发事务的Binlog;
- 性能开销显著:大量同时提交的事务排队等待;
- 持锁完成上述操作,导致大量并发运行中的冲突事务阻塞。

因此,为了解决上面描述的这些问题,泽拓携手华为推出了新的昆仑参天解决方案。它的主要技术要点是:
两个存储节点都有其buffer pool 和redo log,共享存储,类似Oracle RAC架构;
并发控制;
- 页上事务行锁做增删改的并发控制;
- 基于MVCC做select并发控制;
- 避免了事务提交时冲突检测的巨大性能损失;
- 事务运行期写redo log, 并行提交,无需排队;
- 解决了MySQL innodb在同一个事务中 select -> update 的一致性问题。
按页hash分配到参天节点,两节点都可更新;
crash recovery: 两节点同时并行恢复;
对表无PK,UK要求,避免提交时的事务排队的性能瓶颈和长时间持锁阻塞大量冲突事务;
可以合并连接点的更新操作产生Binlog,供MySQL Binlog生态工具使用。

正如我们在简介中介绍的一样,昆仑参天结合了昆仑数据库强大的计算层性能和参天引擎出色的存储处理能力,所以,在详细了解昆仑参天数据库之前,我们还是先简单介绍一下昆仑Klustron分布式数据库和华为参天引擎。
首先,简单介绍一下我们泽拓科技的分布式数据产品Klustron的核心架构:
Klustron的分布式存算分离架构
- 计算层(Klustron-server):多个PostgreSQL实例构成的计算节点负责接受验证应用软件端的连接请求,以及从已经建立的连接中接受SQL查询请求,执行请求,然后返回查询结果;
- 存储层(Klustron-storage): 三个或者更多个MySQL8.0实例构成的存储节点组成一个存储集群(storage shard,简称shard),每个shard 存储着一部分用户表或者表分区;
- 元数据集群存储着Klustron 集群的元数据包括拓扑结构、节点连接信息、DDL日志,commit log,和其他集群管理日志等;
- cluster_mgr集群负责维护正确的集群和节点状态,实现集群管理、集群逻辑备份和恢复, 集群物理备份和恢复、水平弹性伸缩等功能。

接下来,我们再简单了解一下华为参天引擎:
参天引擎是华为存储推出的一款基于共享存储,并且支持多点写入的存储引擎。参天引擎的主要特点是:
- 采用全局分布式缓存技术保证跨节点数据一致性,实现多读多写集群;
- 分布式MVCC技术,极大提升MVCC事务提交性能;
- 采用多活集群高可用技术,实现节点故障快速切换。
如下图所示,右边的参天引擎和传统的mysql一主两从架构不同的地方在于,它通过内部的各个管理模块(集群管理,资源管理,缓存管理,锁资源管理等)支持双主并发写入,以及高可用。
02 昆仑参天数据库的架构与核心技术
昆仑参天数据库的架构与优势
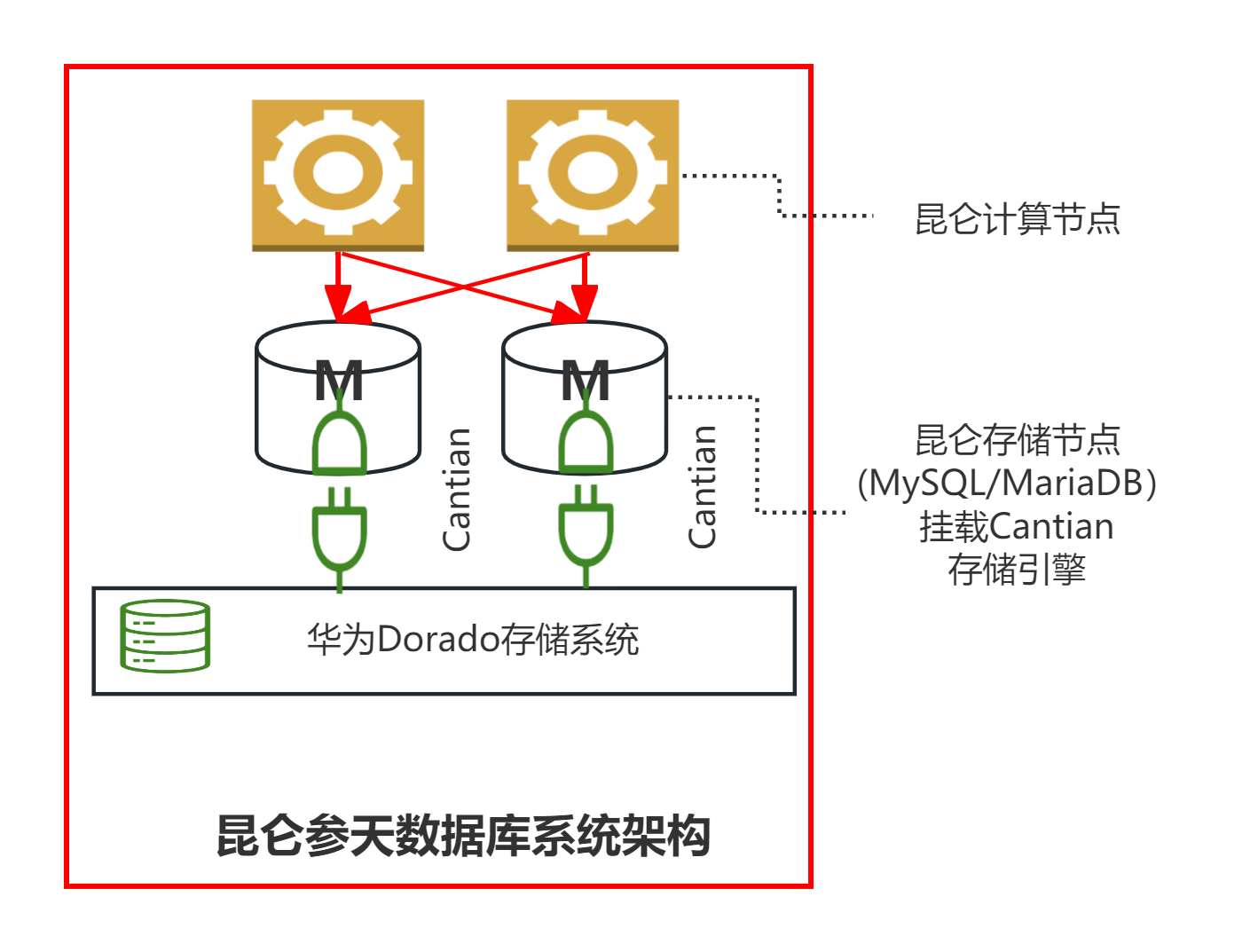
昆仑参天数据库的存储节点使用参天引擎。
- 不再使用其他存储引擎, 包括innodb;无需启用Binlog,但是可以生成Binlog;
- catalog存在参天引擎;
- 完整保留MySQL的SQL 语法,连接协议,以及事务处理功能;
- 数据在参天存储系统多副本存储,基于其高可用能力,可以多机房部署存储系统;
- 参天可以生成合并两主节点数据更新的Binlog。
极致性能。
- 存储节点无需输出Binlog,事务处理的并发度和性能大幅提升;
- 避免了特殊情况下MySQL Binlog复制固有的主备延时等问题;
- 华为高性能存储系统高IO带宽低延时:最根本的性能保障;
- 双主节点,更好的读写扩展能力,透明的读一致性;
- 更短的RTO时间(参天引擎高速并行恢复 VS. MySQL两层串行恢复)

昆仑参天数据库的适用场景
昆仑参天数据库具备以下这些特点:
在更少的约束条件下实现高性能。
- 常出现长事务或者大事务;
- 经常查询和更新没有主键和唯一索引的表;
- 偶有复杂查询(多表连接,子查询,窗口函数)。
在重写入负载时更好的写可扩展性。
同时得到读一致性和读可扩展性。
- MySQL读写分离(从备机读)无法非侵入式地实现读一致性。
高性能OLAP 为BI和报表负载(依赖Klustron Tornado)。
更可靠的HA,备机不会因为主备延时而过期失效。
需要更快的崩溃恢复(更短的RTO)。
原本使用Oracle RAC 的用户需要更短的RTO。
真实由于以上这些特点,使得昆仑参天数据库能打破各种限制,对各种条件下的场景有着更广泛的支持。

昆仑参天数据库-优势和价值:
完整保留Klustron的强大功能和生态兼容能力。
- Klustron-server的生态兼容能力,充分利用PostgreSQL社区技术资源;
- 支持JSON,向量(pgvector) 数据管理;
- 支持PostgreSQL和MySQL双协议双语法;
- 支持机器学习(PostgresML, python 存储过程 with ML libs);
- 各类FDW访问各类外部数据源(对象存储,数据库);
- 高级SQL功能(MySQL不具备第2,3条);
- 存储过程,触发器,[物化]视图,CTE;
- 多层级细粒度的访问控制,数据validation&约束;
- OLAP相关查询功能(window function, grouping-sets, cube, roll-up, etc)。
Klustron-server的高性能分布式查询处理技术体系。
- 充分发挥硬件性能。

03 昆仑参天数据库高性能查询处理技术
3.1 分布式并行查询执行技术
在昆仑参天数据库的计算层,我们采用的是和分布式数据库Klustron一样的计算层架构,提供了基于多个计算节点的分布式并行查询技术。
这种分布式查询的基础设施详细来说主要有以下一些要点:
计算节点内 --- 继承自PostgreSQL 并行查询架构。
- 多进程架构(leader,worker)和 Gather机制;
- Parallel Append, Parallel Aggregate, Parallel Join;
- Remote Plan;
- 计算节点内的并行完全使用原有并行查询框架。
计算节点和存储节点之间的并行查询能力 -- Klustron 全新设计和开发。
- 可独立于计算节点的并行查询框架工作,也可与之协作;
- Parallel Remote Scan: 多进程划分和并行执行Remote Scan子任务;
- 利用多个备机提升只读查询的扩展性;
- 降低查询开销;
- 存储节点的支持功能 -- Klustron 全新设计和开发;
- 多个后端连接(线程)中执行同一个客户端连接的查询子任务;
- 事务快照共享技术 。

计算节点与存储节点之间异步通信。
在多个连接异步发送SQL语句,不阻塞等待查询结果;
- 可以用于驱动多个shard并行执行写入命令(update, delete, insert);
可用于单个或者多个节点并行执行只读查询(select)。
异步发出remote plan SQL语句。
支持的plan节点: MergeAppend,Append,ModifyTable;
都发出后再统一等待收集remote plan查询结果;
Parallel Remote Scan: 只读查询任务分解和多线程执行;
把remote scan任务划分为多个子任务,每个子任务返回一个子结果集
- 使用主键或者唯一索引的做range切分;
在多个连接中分别异步发送,以便存储节点并行执行;
多个worker进程可以各自独立分解任务、发送任务、收集和汇总子结果;
Klustron 1.2 及以上版本支持。

读写分离,多个备机执行SELECT。
- 避免影响主节点性能;
- 在同一个shard的多个备机中实现并行。
计算节点和存储节点之间使用Prepared statements。
适用于客户端发送prepared statements 或者plain text statements;
避免存储节点重复解析和优化查询子任务;
优化 LIMIT ... OFFSET 性能:使用fetch(N)增量流式拉取查询结果。
- 中途停止避免无谓的查询执行和结果传输;
- 避免读写临时表引起IO负载暴增。
Kunlun-storage的支持功能。
多个后端连接共用同一个快照(snapshot);
- 多个线程并行执行多个查询子任务,确保查询结果在同一个节点内的一致性。
使用服务器端只读游标来获取结果;
- 避免计算节点物化(materialize) 查询结果到临时表;
- 避免缓存查询结果到存储节点的临时表;
- fetch之间可以执行其他查询或者其他prepared statement的fetch。

下面,我们通过一个简单的例子来说明并行查询:

以上图左边的两张表做两个join查询为例,右边是没有打开并行查询时候的执行计划,我们可以看到,它只是简单的按照分片把原有的查询分拆成几个子查询来分别执行的。两个查询分别需要250和247毫秒。

而开启并行查询后,同时有三个worker线程来执行执行计划,使得执行效率大大提高,查询耗时分别降到92和71毫秒,只有非并行执行的一半不到的时间,性能提升非常显著。
3.2 JIT代码即时编译技术
接下来我们再介绍一下昆仑参天数据库的JIT代码即时编译技术。
首先,我们来看为什么我们要采用JIT技术,大家可以看看下面这张图。

从上图的火焰图中,我们可以看出一个简单查询的表达式执行部分在整个SQL执行过程中所占的比例非常高,因此,如果有方法可以提升表达式计算的执行效率,就可以大大加速SQL的执行过程。而这个刚好就是代码即时编译JIT能够提供给我们的。
在下图中,我们可以看到JIT和常规代码执行的差异。

JIT(Just-in-time compilation)是一种代码在运行是编译的技术。它可以将常规的代码编译过程在执行时对代码进行分析,并确定代码中可被即时编译加速的部分,在这些部分中,由编译或重新编译带来的性能提高将超过编译该代码的开销,从而节省大量的函数调用过程中耗费的资源,进而大大提升代码执行效率。
在上图中,左边是传统的代码执行过程,其中需要进行三次函数调用来执行一个简单的表达式计算,而经过JIT的分析,这个表达式计算只需要若干条简单的汇编指令就可以完成,所以,JIT将这个表达式计算编译成更高效简单的机器指令,进而加速了执行过程。
下图展示了采用了JIT技术前后,SQL的执行过程的对比。

目前,昆仑参天数据库的JIT支持的数据类型包括:
- int, bigint, float, double, decimal
- date, time, datetime, timestamp
- varchar
支持的运算符包括:
- binary algebras:Plus , Minus , Multiply , Div
- binary comparators:GT , GE , LT , LE , EQ , NE, like
- logical operators:And , Or , Not
- unary operators:Abs
- others:Between . . .and , interval
采用JIT技术后,TPC-H 性能提升: 20% ~ 60%+,未来可以达到10倍性能提升!而且计算节点和存储节点都具备JIT 能力。

3.3 Tornado高性能向量化执行引擎
Tornado高性能向量化执行引擎是泽拓最新推出的SQL执行引擎,它通过向量化执行技术,极大的加速了SQL语句执行的效率。
首先,我们来看看什么是向量化。向量化是基于SIMD(single Instruction Multiple Data)技术,它是通过批量处理同一指令的不同数据来加速代码的执行过程。
SIMD历史
20世纪70年代首次引用于ILLIAC IV大规模并行计算机;
20实际90年代大规模应用到消费级计算机:
- 1996年Intel推出了X86的MMX指令集扩展;
- 1999年Interl推出了全面覆盖MMX的SSE指令集扩展;
- ... SSE3、SSE4、AVX、AVX2等指令集扩展。
从下图中,我们可以简单了解SIMD是如何批量处理a+b这个操作的。

目前,很多分析型数据库都采用了向量化执行的技术,尤其是分析型数据库,比如ClickHouse,DukeDB等,极大加速了分析型计算的执行过程。
泽拓的Tornado向量化执行引擎目前的架构如下图:

首先,Tornado需要把数据在内存中转换成列式存储,然后通过向量化函数和操作符用pipeline的方式进行执行。
下图中,我们可以对比一下Tornado的执行过程。

下面,我们通过一个例子来看看实际的处理过程。

上图的例子中,Tornado先讲a和b的值转换为列存,然后批量处理a+b这个操作,进而通过filter和aggregate算子完成这句SQL的执行。
下图中,我们可以看到向量化物理算子是如何使用SIMD指令进行工作的。

04 Q & A
Q:昆仑参天数据库计算节点是不是可以有多个?存储节点呢?
A:是的,计算节点可以有多个,但存储节点目前只能有两个。这是由于目前,参天引擎只支持双主。也就是说,计算节点可以按需配置个数,但存储节点只有两个,但是两个存储节点能同时写入。