
Klustron技术分享:存储集群的Fullsync机制
Klustron技术分享:存储集群的Fullsync机制
引言
Klustron作为一款能全面支持金融,证券等强一致性场景的分布式数据库,其持续提供服务的能力显得尤其重要。Fullsync(强同步)是Klustron为了保证数据安全性的关键特性,通过主备强同步及建立在此之上的高可用技术(Fullsync HA)完全保证了在意外故障情况下数据的安全。
本期的Tech Talk将主要介绍Fullsync特性及其基础上的HA技术,期望能让大家在对于这一关键特性有认识的同时,对Klustron有一个更为深入了解。
本文金句: Fullsync机制是Klustron的一种存储集群高可用机制,它用于确保一个存储集群在发生问题时,可以按需选举出新的主节点,确保集群能持续提供服务,从而实现高可用。
01 Klustron简介:
首先,我们简单介绍一下我们泽拓科技的分布式数据库产品Klustron。下图为Klustron的整体架构图,从图上可以看出,Klustron是一款存算分离的分布式数据库产品。

作为一款分布式数据库产品,Klustron具备了以下一些强大能力:
弹性伸缩的计算和存储能力
数据分区(partition): hash, range, list
- 任意数量和类型的分区列
数据分布(distribution)
- auto, random, mirror, table grouping
自动、柔性、不停服、无业务侵入、终端用户无感知
金融级高可靠性
自动处理软硬件和网络故障和机房整体故障
- 数据不丢不乱,服务持续在线
- 确保RTO < 30秒 & RPO=0
自动发现主节点故障并选主和主备切换
HTAP: OLTP & OLAP 互不干扰
OLTP为主:对应用软件等价于使用MySQL或PostgreSQL
OLAP为辅:多层级并行查询实现高性能
多语言存储过程的弹性计算:ML,隐私计算
生态兼容性
支持PostgreSQL和MySQL 两种连接协议和SQL 语法
支持MySQL 常用DDL语法
支持JDBC,ODBC,常见编程语言的PostgreSQL和MySQL 客户端connector
全方位多层级安全性
- 加密存储和传输
- 多层级访问控制机制
02 WHY
为什么需要Fullsync?主要从两方面来看:
业务需求:
可能的故障
主节点硬件故障,断电,OS重启,误杀进程;
主备节点磁盘坏块,磁盘全毁
网络分区、断连、拥塞
金融级高可靠性的要求
- 故障时数据库集群可以读写(自动探测主节点状态,发现主节点故障时自动选主和主备切换)
- 故障时不丢失数据
- 高性能,低延时
- 集群长期不间断工作,自维护
已知解决方案的问题:
Semisync
主节点故障后不可以重新加入集群--- 集群节点数量无法快速恢复
备机ACK超时自动退化为异步,一致性(Consistency) < 可用性(Availability)无法实现金融级强一致性
备机ACK前没有fsync relay log, 备机OS重启(例如 机房/机架/服务器断电)会导致已确认事务的binlog丢失
占用工作线程等待备机ACK,连接较多时需要启动大量线程
不完备,需要外部组件配合实现高可用,不能完成主节点故障发现,选主和主备切换
MySQL Group Replication
- 备机确认收到binlog后,主节点才写入binlog到binlog文件,事务提交前持锁等待时间很长,显著增大本事务延时
- 占用工作线程等待备机ACK,连接较多时需要启动大量线程
03 Fullsync & HA
Fullsync的原理:
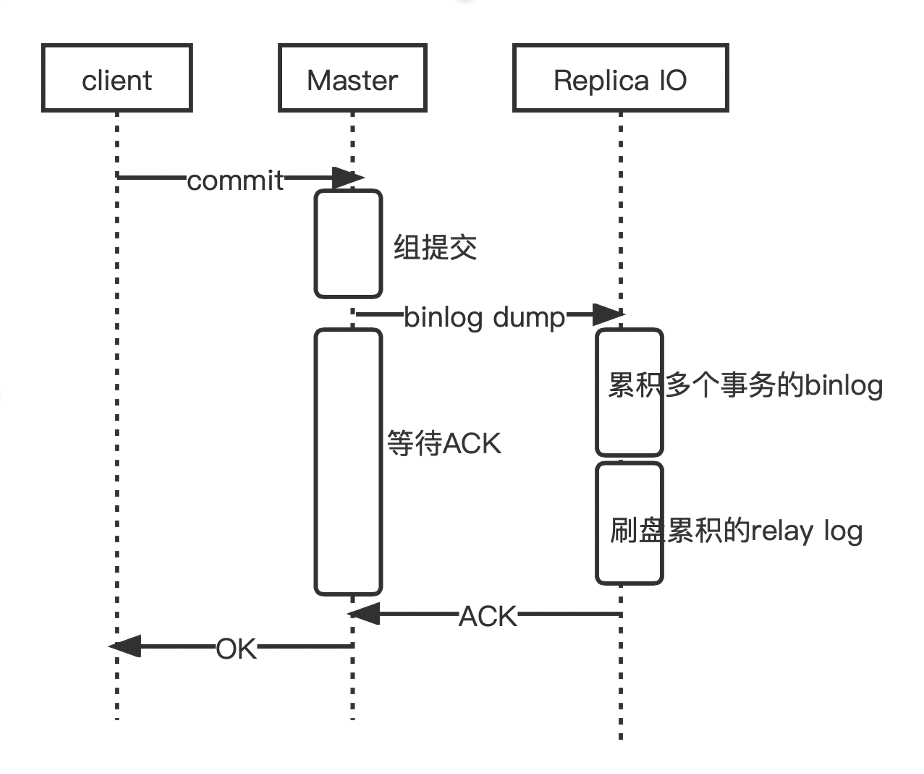
主节点上事务完成提交后等待备机收到其binlog的ACK才返回给客户端(kunlun-server)
主节点上完成提交的任何事务都有至少1个备机(可配置)收到其完整的binlog并持久存储
等待ACK的时机:主节点上事务完成提交流程后返回状态给客户端之前已经完成提交流水线
备机汇集多个事务的binlog一次性写入relay log文件并且刷盘(fsync)然后发送ACK
需要等待fullsync ACK的语句
- 所有做binlog事务提交语句
- DDL语句,autocommit DML语句
- commit,XA COMMIT ... ONE PHASE
- XA PREPARE
主要流程如下图所示:
另外,还有一些技术细节:
主节点上事务等待Fullsync ACK的细节
等待的内容:本事务已经被足够的备机收到并刷盘,ACK的binlog位置 >= 本事务的binlog位置
等待的方法:不阻塞占用工作线程,挂起会话(THD)直到ACK到来,工作线程继续去处理其他连接的请求
等待ACK 超时后的处理:Fullsync HA更加健壮可靠灵活,即:考虑网络或者IO 随机偶发的抖动,支持选择优先 Consistency 或者 Availability
收到ACK的处理:某个后台工作线程执行目标会话(THD)的事务提交流程中的剩余操作,发送OK包给客户端,客户端语句返回
等待ACK超时的处理:在会话中返回 “fullsync等待超时” 错误给客户端
备机接收binlog的处理逻辑
在磁盘负载、性能以及数据一致性 之间取得平衡
以事务为单位write&fsync binlog fsync:断电或者OS重启后binlog仍然持久保存
ACK:主节点binlog上的一个位置。备机发送ACK:该位置之前的binlog已经持久保存,其所属事务可以返回成功
ACK的发送方法:SQL 语句 或者 扩展的 client API (发送命令)
- SLAVE server_id CONSISTENT TO file_index offset(general log默认不记录该语句)
- mysql_send_binlog_ack() (COM_BINLOG_ACK)(更快,但是需要KunlunBase的mysql client lib)
Fullsync的性能:
从我们测试的情况来看,如下图所示,sysbench写入测试 kunlun-storage fullsync 10倍于社区版MySQL MGR,高于社区版MySQL semisync 30%-100%。
这主要来源于两个方面:
通过批量处理的方式加速了事务提交的速度;
通过异步处理的方式,主节点工作线程无需等待备机ACK,使得主节点处理事务的效率得到加速。

Fullsync HA:
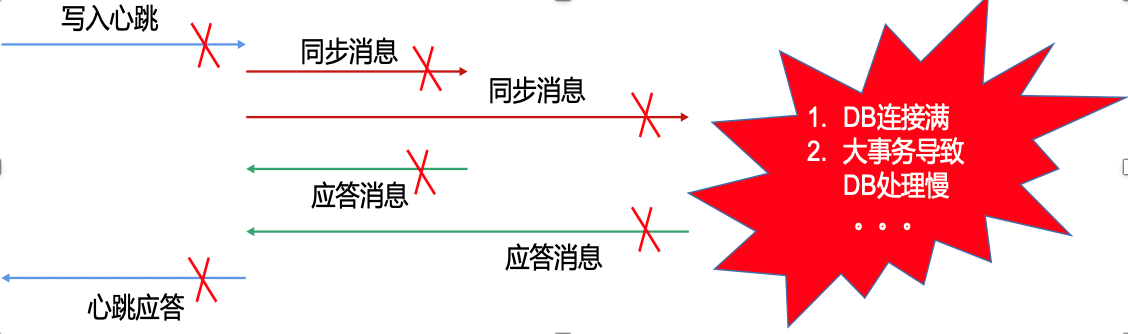
建立在Fullsync基础上的Fullsync HA,通过发送心跳探测故障机制,主动发现节点故障,并根据情况进行重新选主和容灾切换。
故障探测机制如下图所示,通过定期发送心跳消息来探测节点是否正常,如果发生异常则主动发起容灾切换。
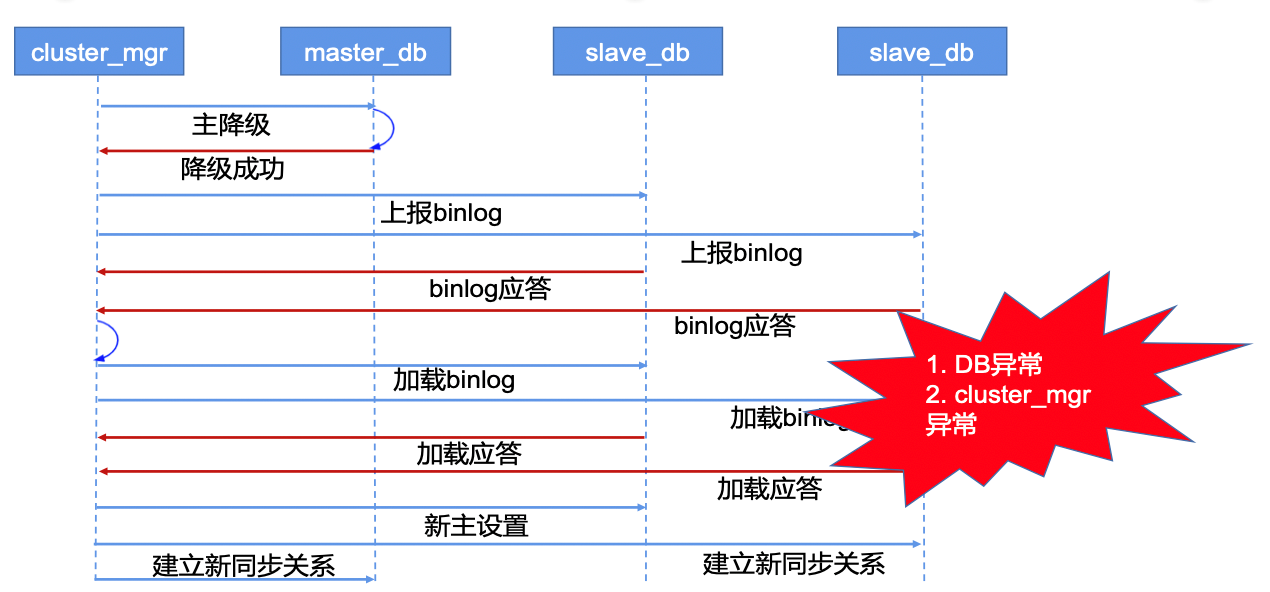
容灾切换流程如下图所示。发生异常时,现将出问题的主节点降级,然后将其所有binlog上报并同步到从节点,同步完成后,从各个从节点中选出新的主节点并完成设置,最后,建立新的同步关系。
04 Q&A
**q1:**Fullsync为啥比semisync快?你们做了哪些优化?性能快多少?为什么官方没做这些优化?
a1: 前面我们已经介绍过了,Klustron强同步性能的提升主要来自于两方面:
- 通过批量处理的方式加速了事务提交的速度;
- 通过异步处理的方式,主节点工作线程无需等待备机ACK,使得主节点处理事务的效率得到加速。
我们测试的结果是sysbench写入测试 kunlun-storage fullsync 10倍于社区版MySQL MGR,高于社区版MySQL semisync 30%-100%。
至于为什么官方没做这些优化,我想可能官方有自己的考虑。比如说为了维持企业版和社区版的差异化,或者资源投入到优先级更高的项目,抑或是为了维护开源生态等。
q2: 什么地方可以试用Klustron?
a2: 对Klustron感兴趣的小伙伴可以从我们的官网下载试用,根据安装文档部署即可。另外,我们在亚马逊的marketplace和阿里云也提供了Klustron的severless服务,大家感兴趣也可以试用。
欢迎大家下载和安装Klustron数据库集群,并免费使用(无需注册码)
Klustron 完整软件包下载:
http://downloads.klustron.com/
如需购买请邮箱联系sales_vip@klustron.com,有相关问题欢迎添加下方小助手微信联系🌹