
Klustron Global MVCC 测试
Klustron Global MVCC 测试
注意:
如无特别说明,文中的版本号可以使用任何已发布版本的版本号代替。所有已发布版本详见:http://doc.klustron.com/zh/Release_notes.html
本文目标:
Klustron作为一款能全面支持金融,证券等强一致性场景的分布式数据库,数据的读一致性是其不可缺少的必要特性。Global MVCC是为了解决分布式环境下读一致性问题的一种全局一致性机制,它通过设置分布式事务的全局数据版本号的方式来获取当前事务的快照,从而实现全局数据的读一致性。
在本文中构造了一个银行账户的场景,去验证在开启和关闭Global MVCC的情况下,查询账户而得到的不同的结果状态,从而证明了在金融级别需要强一致性的情况下,开启Global MVCC的重要性。
01 为什么需要 Global MVCC
首先看看分布式事务的读一致性问题,如下图所示

在没有Global MVCC的情况下:
- 时间A1: Client1发起一个事务,向t1表插入了两条记录(1,'北京')和(2,'深圳'), 假设这两条记录存储的目标shard分别是shard1和shard2。
- 时间A2:Client1进行了事务提交。
- 时间A3:Client2发起了查询t1的操作:select * from t1; 假设在A3时间点,Client1提交的事务在shard1已经写入并提交,但是在shard2上还没有提交。
此时Client2可以看到(1,'北京'),无法看到(2,'深圳'),于是看到了事务的部分结果。
为了解决这个问题,Klustron实现了Global MVCC,其原理主要是通过建立全局快照来获取当前事务的可见数据。
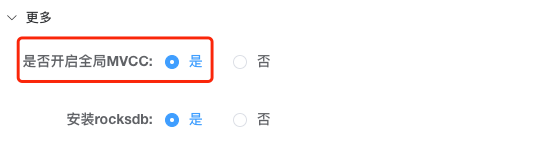
02 开启 Global MVCC
在Klustron中需要在创建集群的时候,启用全局MVCC的选项,然后再创建集群。默认情况下没有开启全局MVCC。
**03 测试案例
3.1 环境准备
通过PG客户端登录计算节点,创建用户和数据库。
psql -h 10.37.129.6 -p 47001 postgres
create user kunlun_test with password 'kunlun';
create database test_db with owner kunlun_test encoding utf8 template template0;
\q
psql -h 10.37.129.6 -p 47001 -U kunlun_test test_db
通过下面的语句查询两个shard对应的ID
select * from pg_shard;

两个shard对应的id分别是1和2。
创建账户表bank_accounts,默认两个分区的存储引擎都是innodb
create table bank_accounts
(
id INT NOT NULL AUTO_INCREMENT,
balance DECIMAL(18,2) NOT NULL,
primary key(id)
) partition by range(id);
create table bank_accounts_p0 partition of bank_accounts
for values from (1) to (501) with (shard=1);
create table bank_accounts_p1 partition of bank_accounts
for values from (501) to (1001) with (shard=2);
插入1000个账户数据
create or replace procedure generate_account_data()
AS $$
DECLARE
v_balance double;
i integer = 1;
BEGIN
while i<=1000 loop
v_balance = ROUND(1000+RANDOM()*9000,2);
INSERT INTO bank_accounts VALUES (i,v_balance);
commit;
i = i+1;
end loop;
END; $$
LANGUAGE plpgsql;
call generate_account_data();
analyze bank_accounts;
导入数据之后,数据平均分布在两个Shard中。

创建Python程序paccupdate.py如下:
import psycopg2.extras
from psycopg2 import DatabaseError
import time
import random
import os
from multiprocessing import Pool
def db_work(num):
print("----开始执行任务%d----" % (num))
conn = psycopg2.connect(database='test_db',user='kunlun_test',
password='kunlun',host='10.37.129.6',port='47001')
update_sql1 = ''' update bank_accounts set balance=balance-100 where id=%s'''
update_sql2 = ''' update bank_accounts set balance=balance+100 where id=%s'''
cursor = conn.cursor()
try:
for i in range(1000):
id = random.randint((num-1)*50+1,(num-1)*50+50)
print(f"减少的id为:{id}")
cursor.execute(update_sql1, [id])
id = random.randint(1000-num*50+1,1000-num*50+50)
print(f"增加的id为:{id}")
cursor.execute(update_sql2, [id])
conn.commit()
time.sleep(1)
finally:
cursor.close()
conn.close()
print("----任务%d执行完毕----" % (num))
def main():
po = Pool(4)
for i in range(1,5):
po.apply_async(db_work,(i,))
print("----开始----")
po.close()
po.join()
print("----结束----")
if __name__ == "__main__":
main()
- 创建了4个线程
- 每个线程每个循环执行一次转账事务,随机取一个shard中的账户,将其账户余额减100;随机取另外一个shard的账户,将其账户余额增加100。
- 每个线程执行1000次转账事务,每次循环之间睡眠1秒。
3.2 Global MVCC 的测试一两个 shard 存储引擎都为 InnoDB
查询所有账户的余额总数为5505457.37

运行paccupdate.py程序,开启4个线程同时对用户账户进行转账操作。
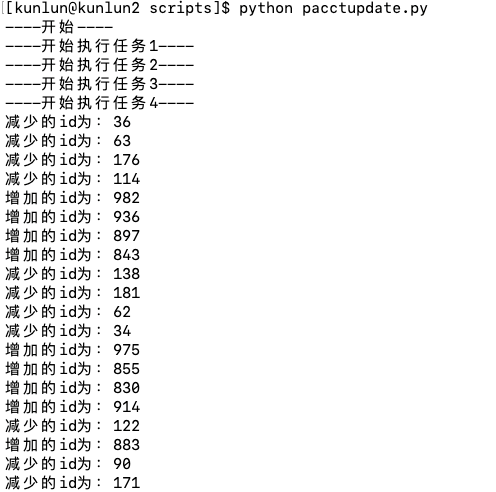
与此同时运行另外一个程序qsum.py,实时查询账户总额
import psycopg2.extras
from psycopg2 import DatabaseError
import time
from decimal import Decimal
conn = psycopg2.connect(database='test_db',user='kunlun_test',
password='kunlun',host='10.37.129.6',port='47001')
select_sql = ''' select sum(balance) from bank_accounts;'''
cursor = conn.cursor()
try:
for i in range(1000):
cursor.execute(select_sql)
res = cursor.fetchall()
for row in res:
balance = row[0].quantize(Decimal('0.01'))
print(f"账户总额是{balance}")
time.sleep(1)
finally:
cursor.close()
conn.close()
查询在paccupdate.py运行过程中,所有账户总额的情况
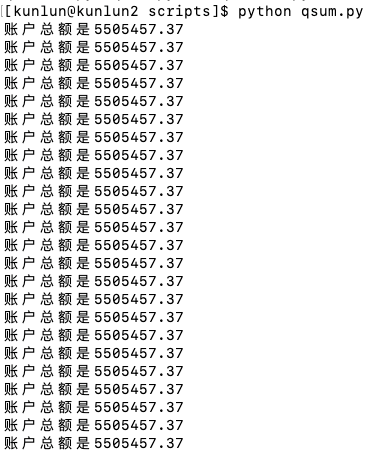
可以看到总的余额在程序运行过程中一直保持不变。
3.3 Global MVCC 的测试一两个 shard 存储引擎都为 RocksDB
创建一个新的账号表为bank_accounts_rocksdb,其两个Shard的存储引擎都是
create table bank_accounts_rocksdb
(
id INT NOT NULL AUTO_INCREMENT,
balance DECIMAL(18,2) NOT NULL,
primary key(id)
) partition by range(id);
create table bank_accounts_rs_p0 partition of bank_accounts_rocksdb
for values from (1) to (501) with (shard=1,engine=rocksdb);
create table bank_accounts_rs_p1 partition of bank_accounts_rocksdb
for values from (501) to (1001) with (shard=2,engine=rocksdb);
insert into bank_accounts_rocksdb select * from bank_accounts;
analyze bank_accounts_rocksdb;
测试步骤参考2.2, 将Python程序对应的目标表更换为bank_accounts_rocksdb。运行四个进程模拟进行转账操作
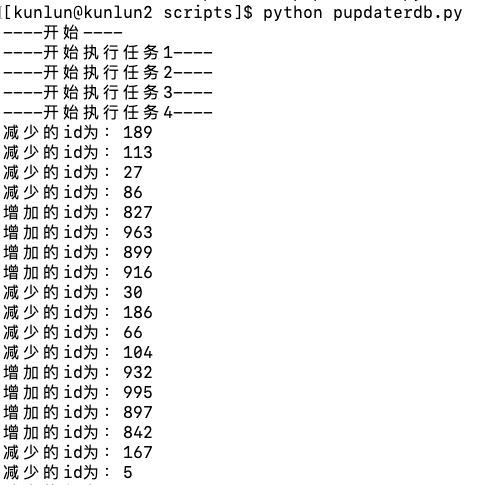
与此同时在另外一个session中循环查询账户的总的余额。qsumrdb.py中计算sum的表修改为bank_accounts_rocksdb
当账户表shard的存储引擎更改为RocksDB,Global MVCC保证了在多用户转账过程中所有账户的余额保持不变。
3.4 Global MVCC 的测试一两个 shard 存储引擎一个为 InnoDB ,另一个为 RocksDB
创建表bank_accounts_mixed,两个Shard的存储引擎分别为InnoDB和RocksDB。
create table bank_accounts_mixed
(
id INT NOT NULL AUTO_INCREMENT,
balance DECIMAL(18,2) NOT NULL,
primary key(id)
) partition by range(id);
create table bank_accounts_mixed_p0 partition of bank_accounts_mixed
for values from (1) to (501) with (shard=1);
create table bank_accounts_mixed_p1 partition of bank_accounts_mixed
for values from (501) to (1001) with (shard=2,engine=rocksdb);
insert into bank_accounts_mixed select * from bank_accounts;
analyze bank_accounts_rocksdb;
测试步骤参考2.2, 将Python程序对应的目标表更换为bank_accounts_mixed。运行四个进程模拟进行转账操作

与此同时在另外一个session中循环查询账户的总的余额。qsummix.py中计算sum的表修改为bank_accounts_mixed

同样的当账户表的两个shard的存储引擎分别更改为InnoDB和RocksDB,Global MVCC保证了在多用户转账过程中所有账户的余额保持不变。