使用 Kibana 查看节点日志信息
使用 Kibana 查看节点日志信息
前言
Klustron 支持图形化一站式统一查看和检索系统各节点的日志,这比登录每个服务器查看和检索日志文件要便利很多。具体来说,Klustron 通过ElasticSearch的FileBeat收集各节点的日志文件更新,存储到用户独立安装的ElasticSearch集群中,这样就可以通过Kibana 实时查看和检索 集群中所有类型的节点,包括clustmgr、nodemgr、存储节点和计算节点的日志。
对于存储节点,除了可以检索错误日志外,还可以查看执行过的SQL语句日志general_log和慢查询日志slow_log;对于计算节点,还可以启动SQL日志,这是计算节点发送给存储节点的所有SQL语句, 启用的方法是set enable_sql_log=on 。不过SQL日志对性能损耗较大而且占据大量磁盘空间。
日志扩展说明
Klustron的每一条日志(包括错误日志,general_log, slow log)在原有内容基础上,还增加了下述3个字段以便把集群所有的计算节点和存储节点打印的日志,关联到每个客户端会话以及每一个SQL语句。其中重要的新增字段包括:
- comp_node_id
这是每个计算节点在集群中的唯一的不变的ID。存储节点打印的所有日志都有此字段,以便跟踪这条日志对应哪个计算节点中的客户端连接。
- global_conn_id
这是每个计算节点中的会话ID,也是计算节点进程组中处理一个用户连接的工作进程的ID。global_conn_id与comp_node_id一起标识了集群中每一个客户端会话。这两个字段相同的日志,对应的就是同一个会话中的行为。不过要注意的是,一个进程结束后,其进程号有可能被未来启动的进程使用,并且通常不会立刻重用而是经过较长时间(通常至少几个小时)才会回绕。因此,长期运行的Klustron集群的日志中,具有相同的global_conn_id与comp_node_id的日志,未必一定由同一个用户会话中的行为产生。但是在时间上面接近的通常是同一个会话的行为。并且连接断开(即会话结束)也会打印日志,因此仔细辨析可以准确地区分出不同的会话。
- cluster_stmt_id
Klustron集群会给每个计算节点的每个连接中 执行的每一个语句分配一个从1开始自增的编号,标识此连接中的语句。cluster_stmt_id,global_conn_id与comp_node_id 这3个字段可以唯一标识每个SQL语句。这样可以在日志中看到执行来自客户端的每个SQL语句,集群内各个节点各自的操作和日志。
在日志中可以搜索上述字段名称和值来找到一个特定连接中的系列操作,以及集群相关节点执行一个特定语句的具体操作。
更多说明
另外,在SHOW PROCESSLIST等语句中,也新增了cluster_stmt_id,global_conn_id与comp_node_id 字段,以便把各个存储节点中针对集群的每一个客户端连接的后端连接关联起来,这些信息也会有助于DBA观察系统的各节点的运行状况。 存储节点对更多行为打印了日志,包括执行关键命令和SQL语句,以及重要的事件,比如因为各种原因而断开连接等。通过设置print_extra_info_verbosity=N (N是整数)可以控制部分日志是否打印,数字越大越详细,打印的日志越多,设置为0则不打印任何此类日志。
计算节点的SQL日志文件位于其错误日志文件所在的目录,通常也是该实例的数据目录。存储节点的general_log和slow_log位于其数据文件或者日志文件目录中,可以查看每个存储节点实例的配置文件,此文件位于该实例的数据目录中。
另外,存储节点和计算节点的语句日志和慢查询日志的启用和控制,分别与MySQL 和PostgreSQL 完全相同,此处不再赘述。并且计算节点的SQL语句日志和慢查询日志也是记录在其错误日志文件中的,这一点与PostgreSQL也完全相同。 上述所有日志文件,以及存储节点的binlog文件,都需要人工清理,这与MySQL和PostgreSQL也是相同的。
使用Kibana的预备条件
安装 clustmgr、nodemgr、存储节点、计算节点时,需要提前以下两个包:
wget http://zettatech.tpddns.cn:14000/thirdparty/efk/elasticsearch-7.10.1.tar.gz
wget http://zettatech.tpddns.cn:14000/thirdparty/efk/kibana-7.10.1.tar.gz
同时,cluster_and_node_mgr.json中增加以下配置,与cluster_manager、node_manager同级。
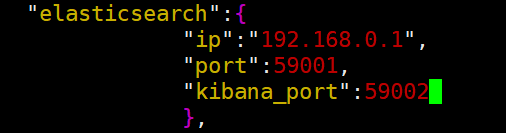
其中字段说明如下:
- elasticsearch: 指定 elasticsearch 的内容;
- ip: 字符串类型,安装 elasticsearch 所在机器,该机器会同时安装 elasticsearch 和 kibana;
- port: 整型,指定 elasticsearch 的端口,默认 9200;
- kibana_port: 整型,指定kibana的端口,默认 5601。
- clustmgr、nodemgr、存储节点和计算节点都成功安装后,就可以使用 kibana 查看日志了。
使用示例
1.1 浏览器输入部署好的kibana网址
如:http://192.168.0.1:59002/
初次打开页面如下图:
1.2 添加日志索引
首先如下操作进入创建索引界面,图1
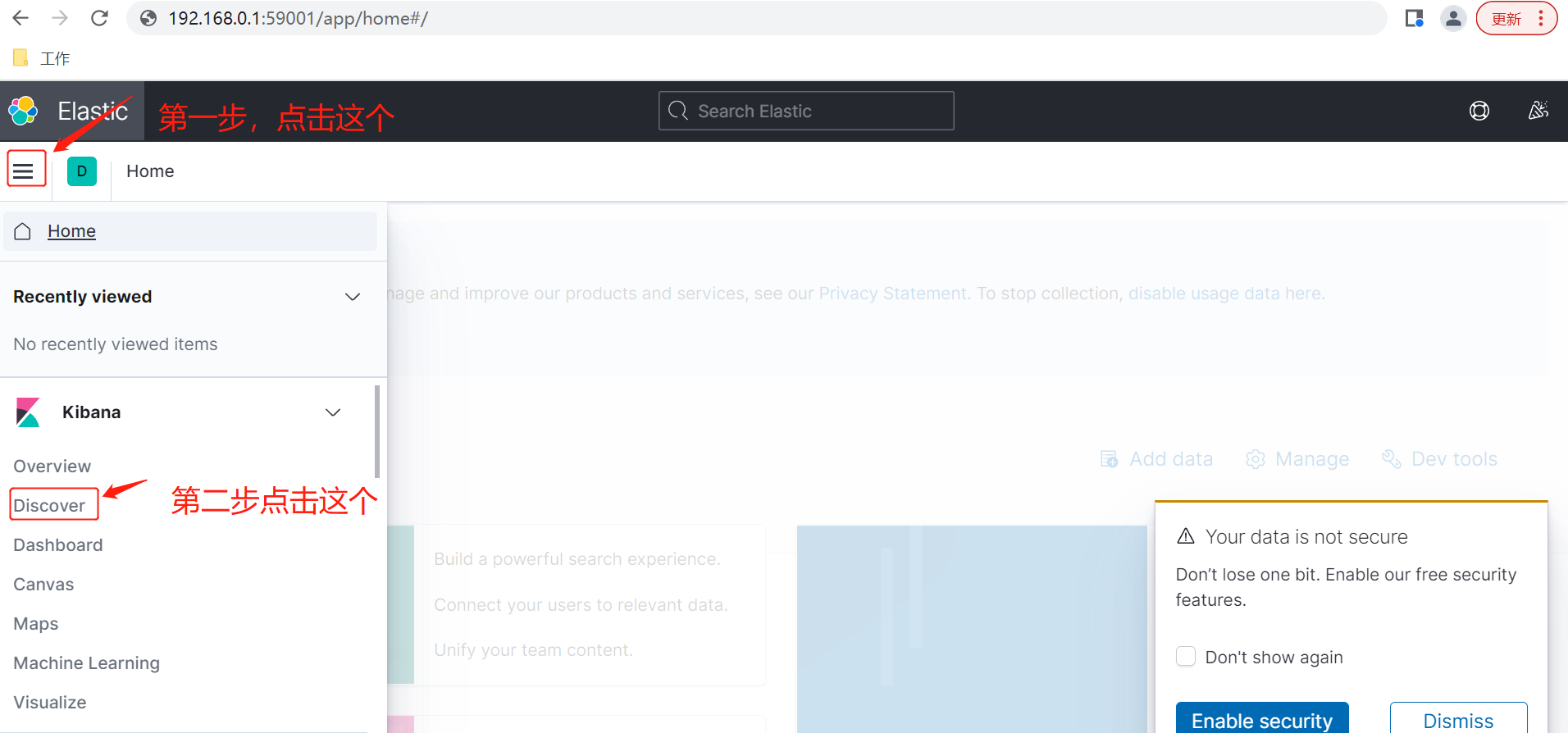
图2

进入到如下界面,图3:
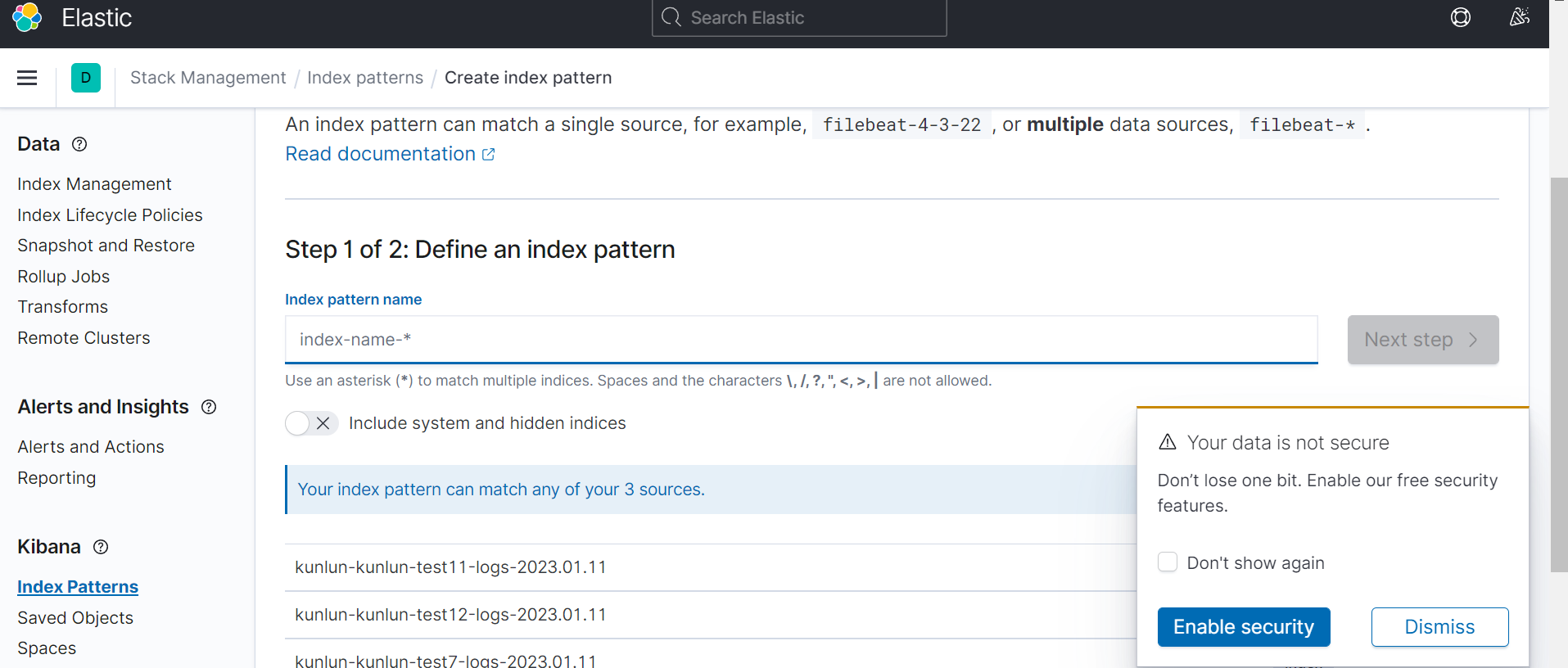
创建索引名,图4:
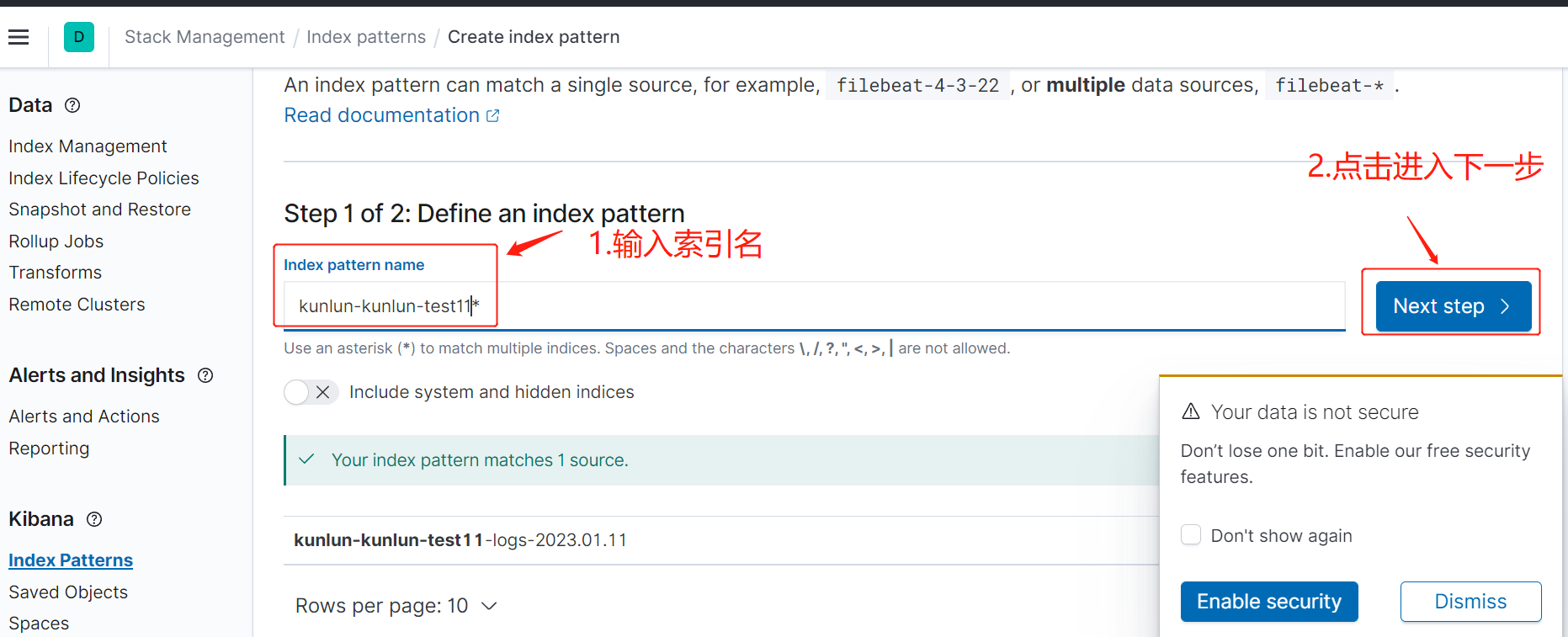
图5
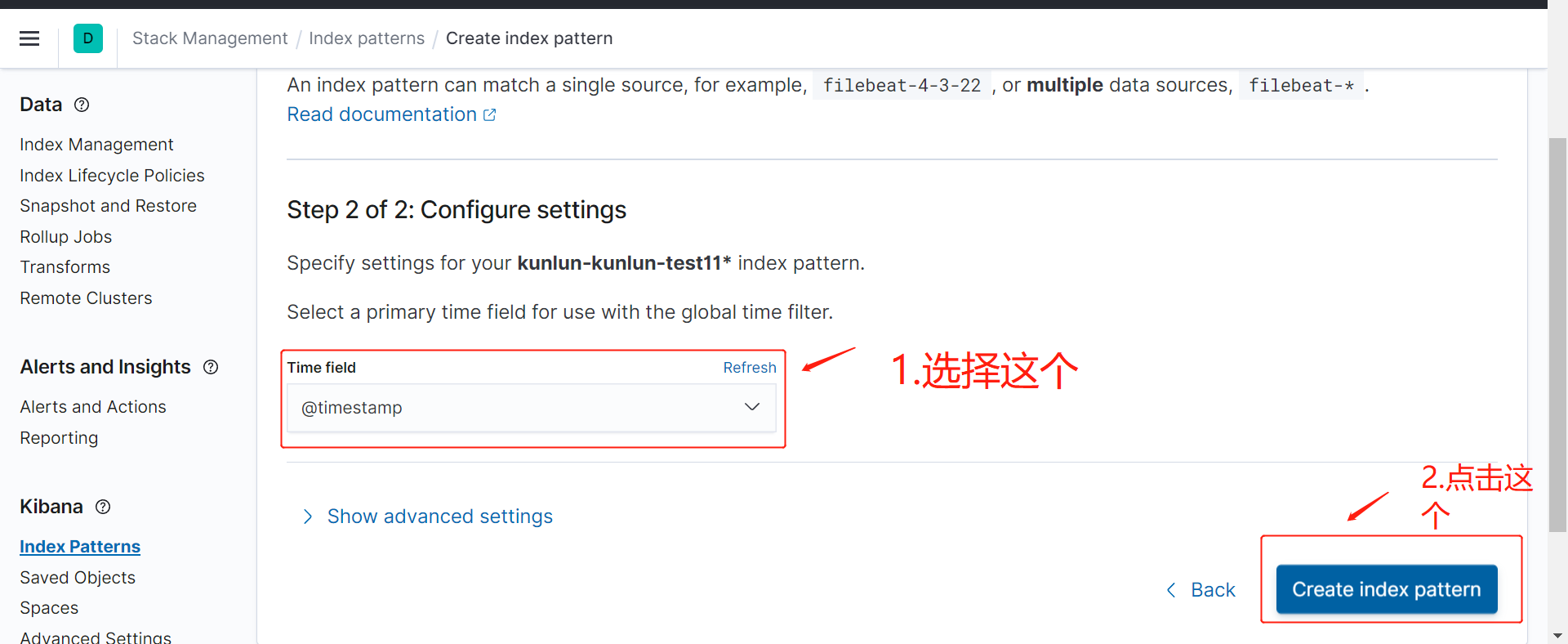
返回到上一级,如图6
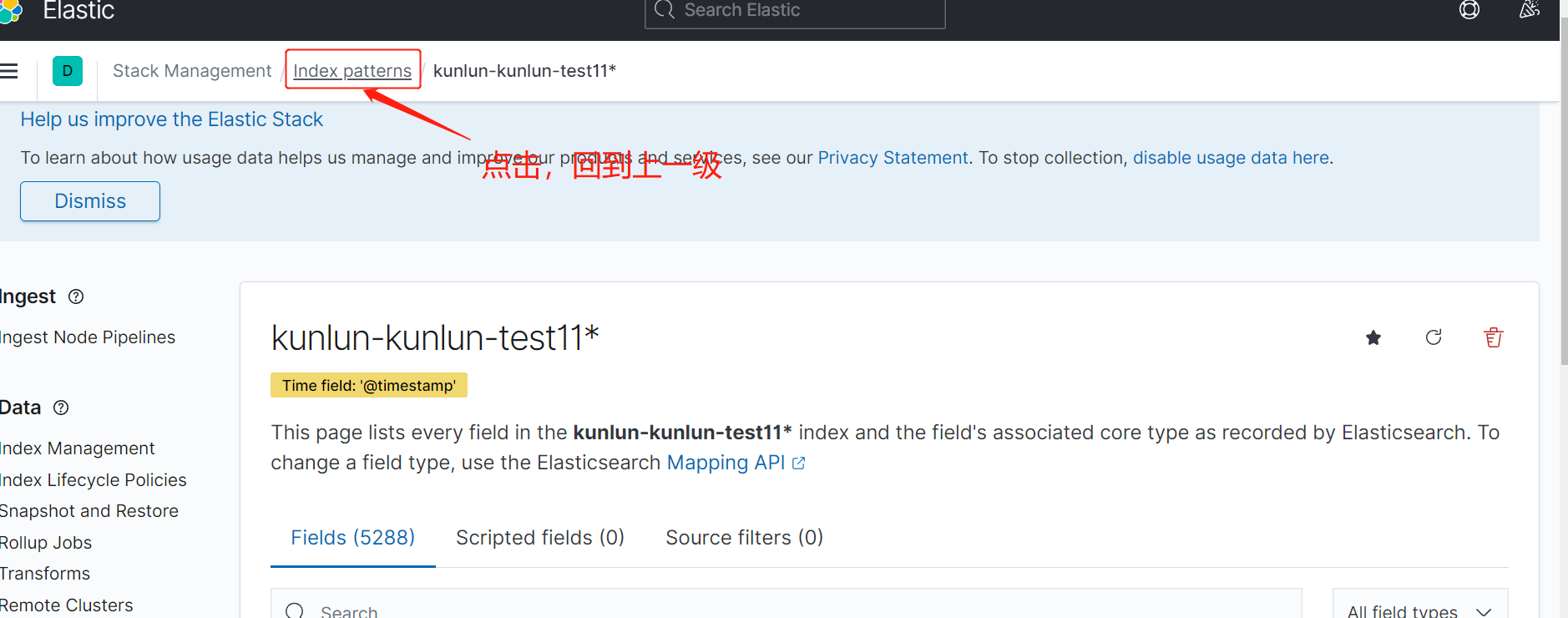
重复步骤,如图2--图5,添加其他节点的索引,如下图6,展示添加了3个节点的索引。
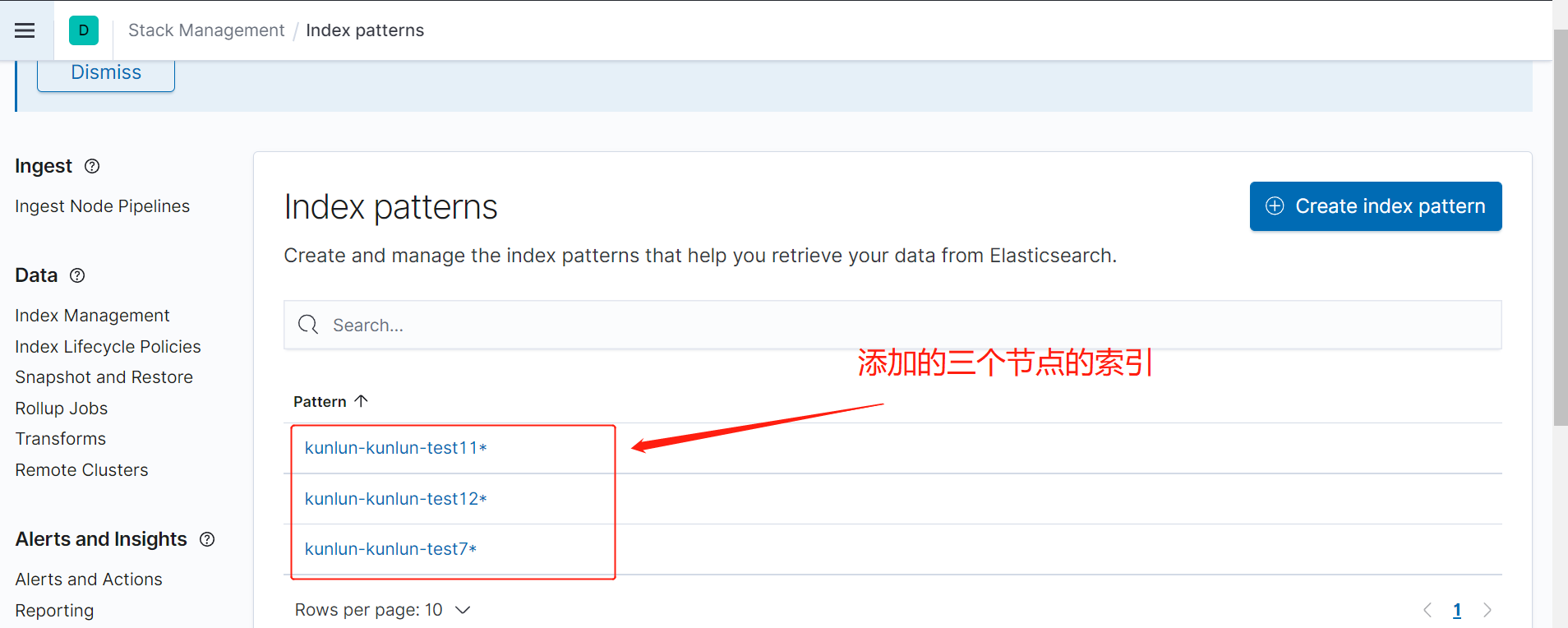
1.3 查看日志,按下图进入的日志查看页面
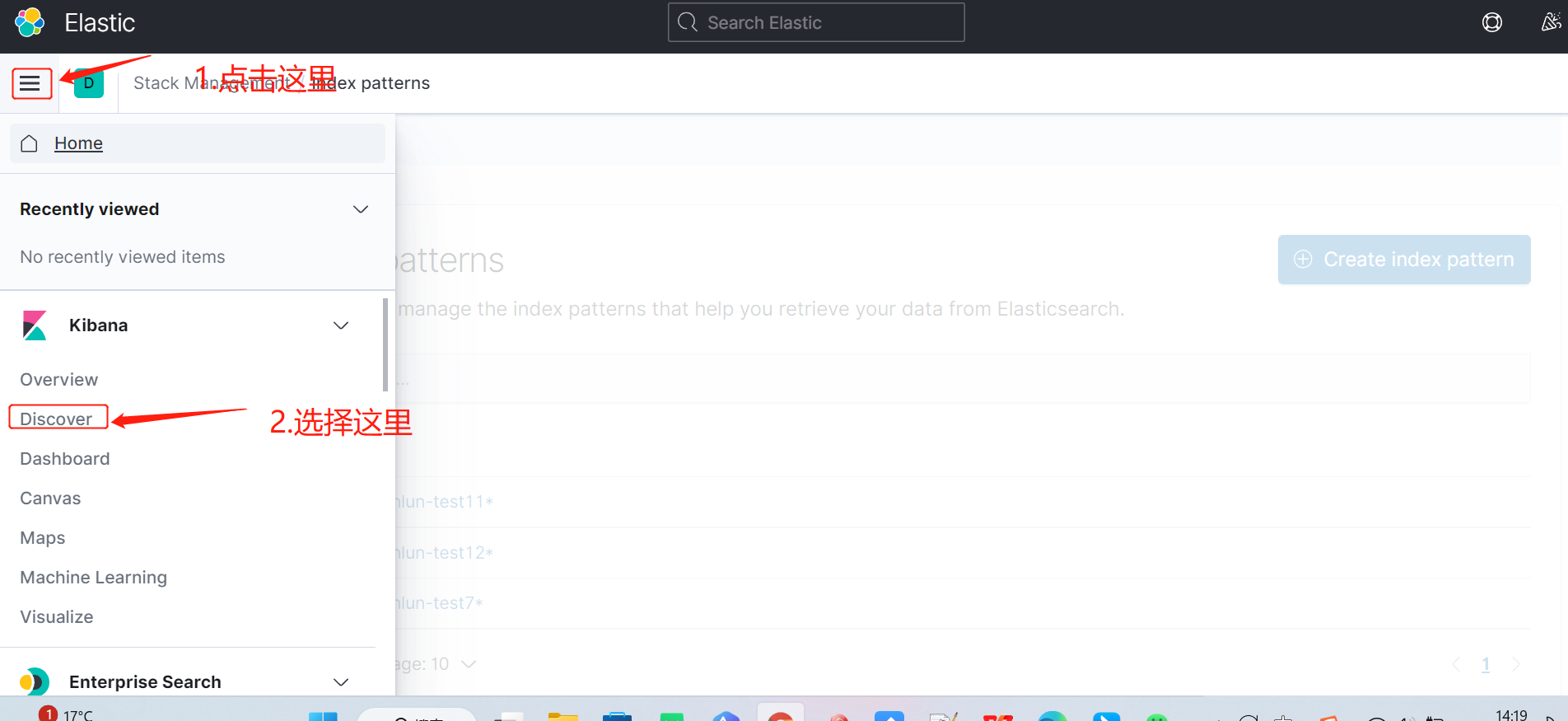
日志页面展示如下图:


1.4 过滤出 nodemgr 日志,
如图位置输入:event.module : "nodemgr"(建议先选择节点索引,根据节点得知对应机器,再查看各模块日志展示)
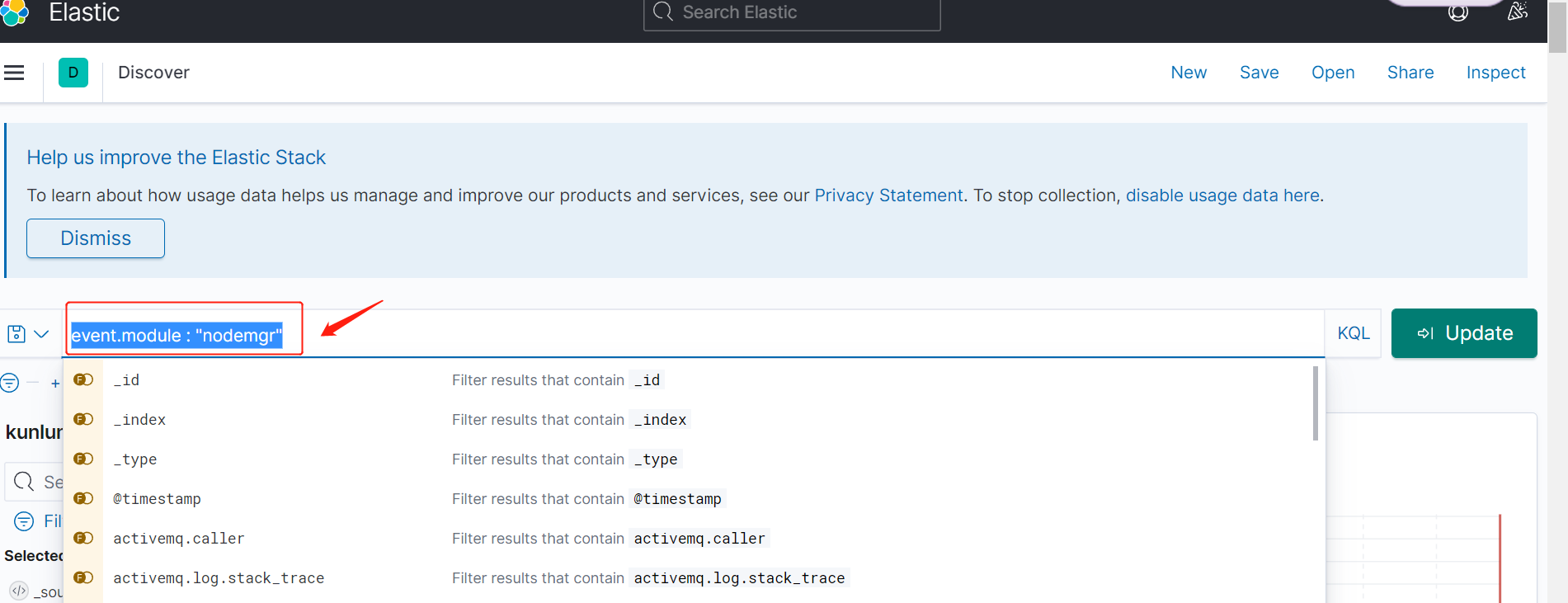
然后输入 enter 键,得到 nodemgr 的实时日志:

1.5 过滤出 clustermgr 日志,
如图位置输入:event.module : "clustermgr",然后输入 enter 键,得到 clustermgr 日志。

1.6 过滤出存储节点(Klustron-storage)的日志
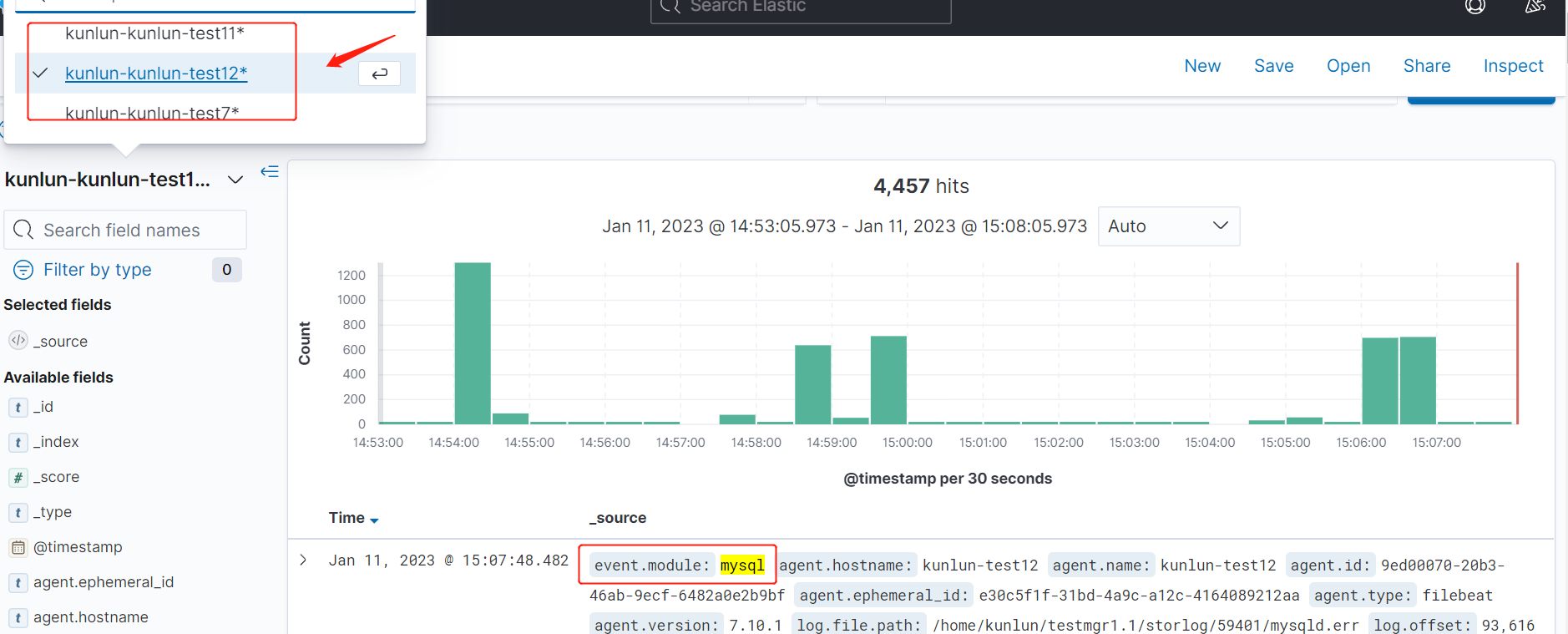
如图位置输入:event.module : "mysql",然后输入 enter 键,得到 mysql 日志。

1.7 过滤出计算节点(Klustron-server)的日志
如图位置输入:event.module : "postgresql",然后输入 enter 键,得到 postgresql 日志。
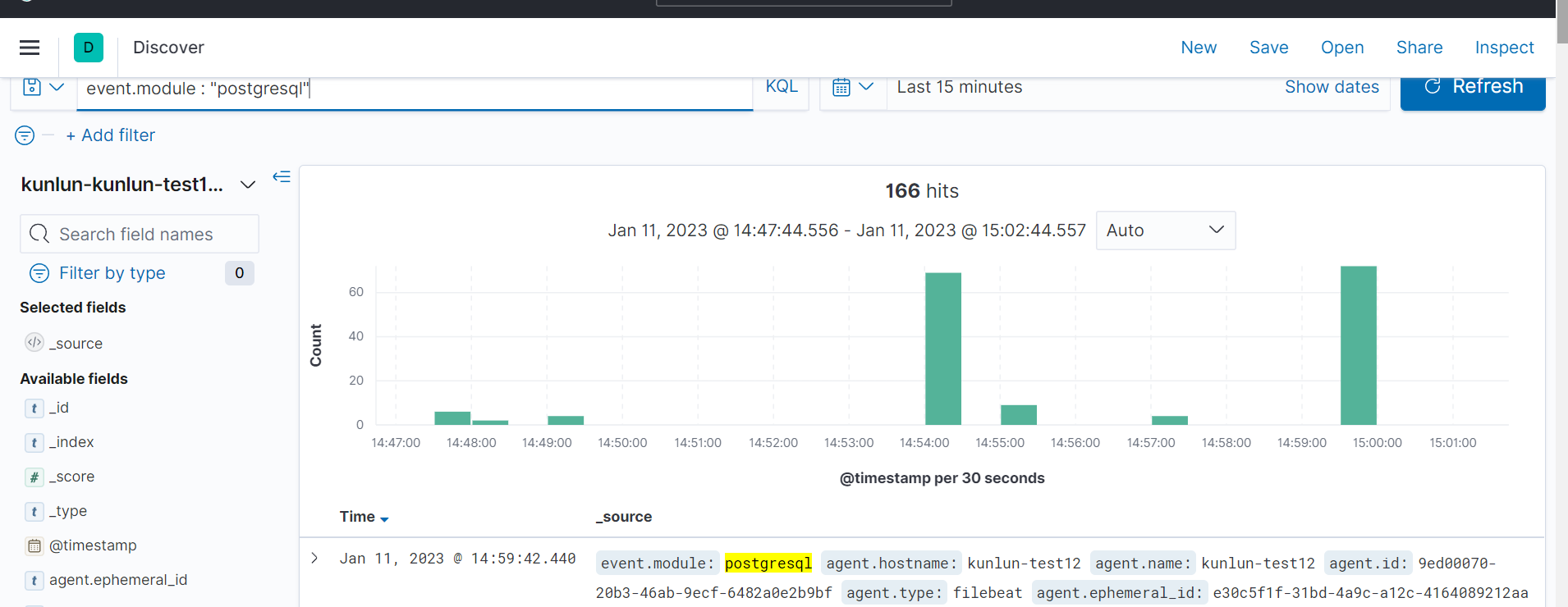
1.8 根据节点索引,过滤日志,
选择mysql模块后,如图箭头处切换节点索引。