
Klustron(原KunlunBase) 快速体验指南
Klustron(原KunlunBase) 快速体验指南
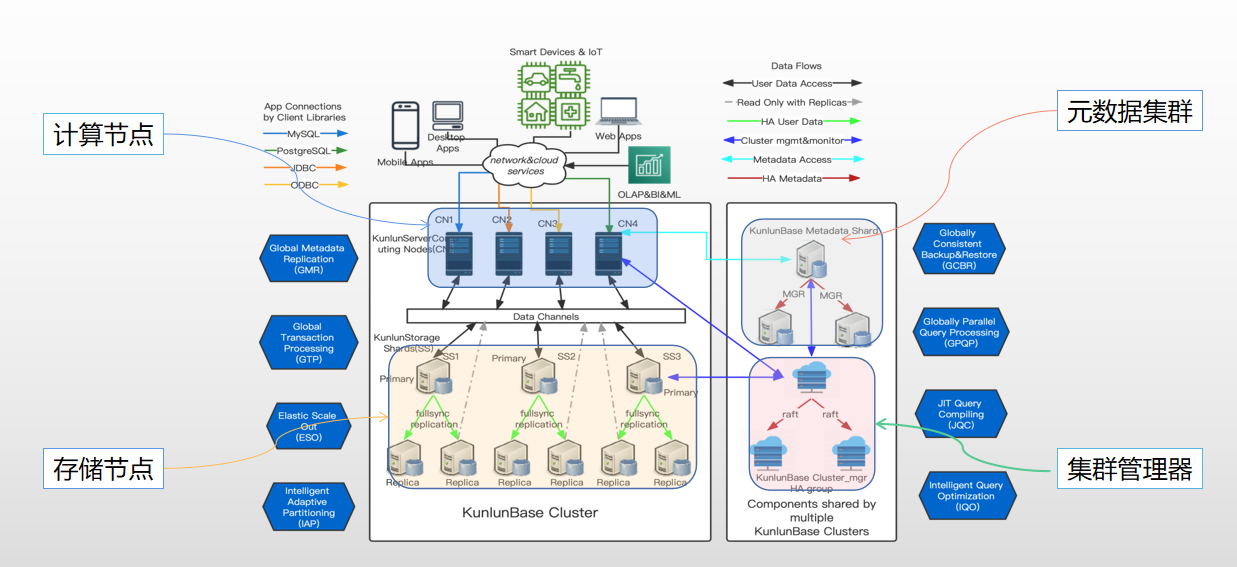
一、基本概念
计算节点:
计算节点使用PostgreSQL客户端协议或MySQL协议接受并验证客户端连接,并通过与集群的存储节点进行交互来执行连接客户端的SQL语句。
计算节点是无状态的,随着工作负载的增长,用户可以添加更多的计算节点,每个计算节点都可以为用户读/写请求提供服务。
计算节点具有全局事务处理能力,对于跨存储节点的数据操作,计算节点通过二阶段提交协议保证数据的一致性和完整性。
昆仑分布式数据库集群的计算节点本地具有所有数据库对象的所有元数据(表、视图、物化视图、序列、存储过程/函数、用户/角色和特权等),但它们不会在本地存储用户数据。相反,计算节点将其存储在存储节点中。
计算节点同时支持Mysql/ Postgresql 两种协议
存储节点:
存储节点是用户&业务数据的具体存放的地方。
每个存储节点都会存储所有用户数据的全部或部分子集,一个存储节点组(包含主从节点)称为一个分片(shard)。
存储节点从计算节点接收SQL指令以插入/更新/删除用户数据或返回数据给计算节点。 存储节点通过基于我们自研的高性能 FullSync 技术实现一主多副本的数据高可靠性。
昆仑数据库的Fullsync(强同步)机制确保一个kunlun-storage的storage shard(存储集群)在提交任何一个事务完成后并且返回给客户端成功确认之前,必须收到fullsync_consistency_level个备机的ACK确认收到了这个事务的binlog。
元数据集群:
元数据节点存储整个昆仑集群的元数据,包括用户的定义数据,节点连接信息,存储节点信息,交易信息等。
集群管理器:
集群管理器作为守护进程运行,维持每一个存储集群及其节点的replication状态、集群计算节点与存储节点之间的元数据和状态同步,集群管理程序也负责处理分布式事务特定故障。
二、快速体验
可以通过 Klustron 多合一 Docker 镜像来快速体验 Klustron 的集群结构和基本功能。Klustron 多合一 Docker 镜像是将 Klustron 集群的节点都放入一个 Docker 镜像,以方便用户进行功能体验而制作的 Docker 镜像。
在该镜像中, 模拟了一个小规模数据集群,该集群具有以下节点:
- 三个 Klustron-storage 节点,构成一个3副本的 Meta Shard;
- 还有六个 Klustron-storage 节点,构成两个 Data Shard, 每个 Shard 的副本数为 3;
- 三个 Klustron-server 节点,构成三个各自独立的计算节点,用于处理客户端的数据请求。该集群的各个 Klustron-storage 节点的 buffer pool size 仅为 64MB, 所以该集群仅可用于功能体验,不能用于性能和压力测试。
使用该镜像来快速体验 Klustron 的步骤为:
第一步:
环境需求: 一台 Linux 服务器,可用内存至少8G,磁盘空间20G以上, 安装了 docker,并且可以直接访问外网。
登录服务器,执行如下命令,安装Klustron 集群 docker 环境:
# 当值支持的VERSION值有: 0.9.2 v1.0.1 1.0.2 1.1.1
VERSION=1.1.1
sudo docker run --privileged --name kunlun1 -p 5401:5401 -p 5402:5402 -p 5403:5403 -p 5404:5404 -p 5405:5405 -itd registry.cn-hangzhou.aliyuncs.com/kunlundb/kunlun:$VERSION bash -c 'bash /kunlun/start_kunlun.sh'

演示环境成功部署
第二步:
进入Klustron 数据库集群服务器:#docker exec -it kunlun1 /bin/bash
检查计算节点:执行如下图中的指令, 显示三个计算节点已经运行。 
检查元数据集群:执行如下图中的指令, 显示三个元数据节点集群已经运行。 
第三步:
检查存储节点: 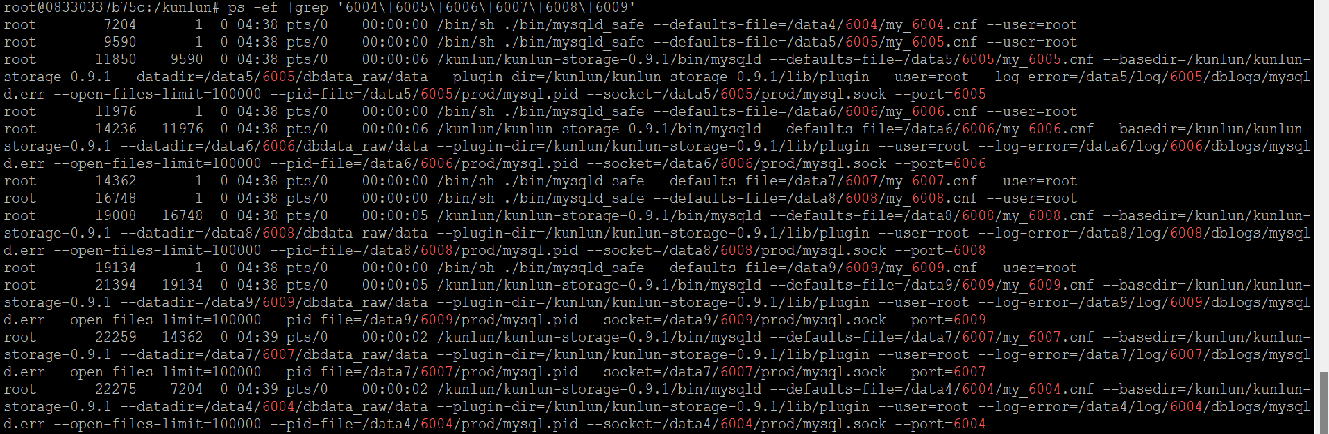
说明:
- 6004 端口是存储节点分片1的主节点, 6005,6006 是存储节点分片1的两个从节点
- 6007 端口是存储节点分片2的主节点, 6008,6009 是存储节点分片2的两个从节点
第四步:
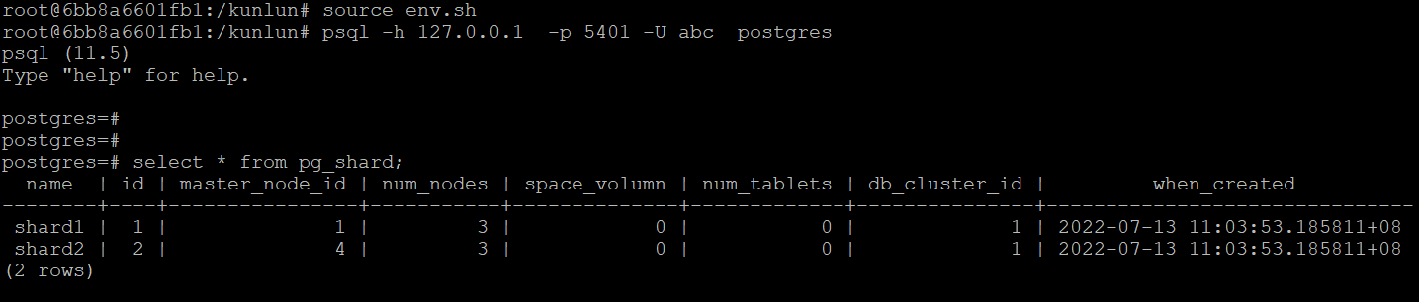
连接数据库,检查集群分片存储信息:
#source env.sh
#psql -h 127.0.0.1 -p 5401 -U abc postgres
第五步:
创建普通表:
CREATE TABLE testtable1 (id int primary key);
创建分区表:
CREATE TABLE testtable (id int primary key, name char(8)) partition by hash(id);
CREATE TABLE testtable_p1 PARTITION OF testtable FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE testtable_p2 PARTITION OF testtable FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE testtable_p3 PARTITION OF testtable FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE testtable_p4 PARTITION OF testtable FOR VALUES WITH (MODULUS 4, REMAINDER 3);
检查表分布情况:
select relname,relshardid from pg_class where reltype<>0 and relname like '%testtable% ';
快速体验补充说明
快速体验环境曾经是一个2个shard存储的MGR集群,从Klustron-1.2版本开始,此docker镜像中的元数据集群和存储集群都是用RBR集群,不再使用MGR。在实际部署时,昆仑数据库时可以部署为单shard的方式,也可以部署为多个shard的方式, 完全取决应用环境的需求。
当昆仑数据库部署为单shard的方式, 环境需要的硬件配置与一个单节点的Mysql 一样, 但在性能和可靠性方面比单节点Mysql有很大的提升。
单shard 昆仑数据库可以动态扩容到多个shard集群, 以支持更大数据量及更高的负载,通过扩容, 数据库的处理能力可以获得线性提升,快速解决性能和容量的扩展性问题。
对于使用 driver 来连接数据库而言,可以使用以下配置:
- host= 容器运行主机的 ip 地址;
- port= 映射的端口号,例子中为 5401 或 5402 或 5403;
- user=abc
- password=abc
- database=postgres