
Klustron vs. Community PostgreSQL: PostGIS Performance and Scalability Test
Klustron vs. Community PostgreSQL: PostGIS Performance and Scalability Test
The Klustron database, with its compute-storage separation and distributed architecture, offers superior elastic computing performance and scalability compared to the traditional community version of PostgreSQL. This article utilizes publicly available New York taxi data, loading it into both Klustron and community PostgreSQL environments to run typical analytical SQL queries and draw performance comparison conclusions.
Furthermore, Klustron's design allows for the horizontal scaling of computational power. When business demands increase, it enables the flexible expansion of both computing capabilities and storage capacity. This approach offers a clear advantage over the vertical-only scaling possible with community PostgreSQL, ensuring Klustron excels in overall throughput and storage capacity.
PostGIS is one of the most renowned functional extensions within the PostgreSQL community, its history and fame parallel to PostgreSQL itself. It's virtually the de facto standard in GIS data management.
With the introduction of PostGIS support in Klustron version 1.3, users can mount PostGIS onto Klustron's compute nodes just as they would with PostgreSQL, unlocking all of PostGIS's functionalities. This effectively turns Klustron into a distributed PostGIS database, significantly amplifying its capabilities in managing and computing GIS data. Given that GIS data computations (such as spatial relationship determination and spatial object computations and generation) are far more demanding than simple data types like numbers or strings, relying on PostGIS with standalone PostgreSQL could quickly lead to computational bottlenecks. In contrast, Klustron's distributed model allows for the utilization of an unlimited amount of computing resources by merely adding more compute servers, making it a straightforward and cost-efficient solution.
In the implementation layer, we adapted PostGIS-3.3.4 to slightly modify GIS data storage read-write operations, enabling the integration of GIS data with Klustron's storage nodes. Moreover, extensive development was undertaken to enable spatial computation functions of PostGIS to be executed on the storage nodes. This approach not only enhances GIS query performance through parallel processing but also eliminates unnecessary data transfers between compute and storage nodes.
MySQL-8.0 supports GIS data storage and computation. Since MySQL-5.7, the Oracle MySQL team has revamped its GIS implementation, adopting boost.geometry as the computational kernel for GIS, achieving significant improvements in performance and accuracy. Particularly, MySQL-8.0 has adopted a coordinate system collection nearly identical to PostGIS, making it widely applicable for users globally. They can utilize local coordinate systems exactly as they would with PostGIS. Consequently, Klustron's PostGIS extension is functionally equivalent to PostgreSQL+PostGIS, while substantially outperforming it in both efficiency and scalability.
As demonstrated below, our tests show that Klustron's PostGIS is fully compatible with PostGIS at the functional level and also offers superior performance compared to PostGIS mounted on a standalone PostgreSQL.
This article employs publicly available New York taxi data, loaded into both Klustron and community PostgreSQL environments, to run typical analytical SQL queries and draw performance comparison conclusions.
01 Test Environment
Test Environment One: (Klustron)
| Node Type | IP | Port |
|---|---|---|
| Compute Node | 192.168.0.19 | 47001 |
| Shard1 Primary Node | 192.168.0.21 | 57007 |
| Shard2 Primary Node | 192.168.0.19 | 57003 |
| Shard3 Primary Node | 192.168.0.20 | 57005 |
| XPanel | 192.168.0.19 | 40180 |
Hardware configuration for 3 test servers is identical: CentOS 8.5 Linux 64-bit, AMD Ryzen 9 7950X 16-Core (32 threads), MEM: 128GB, Storage: 2TB SSD (M.2 SSD PCIE 4)
PostGIS: 3.3.4
Test Environment Two: (PostgreSQL 11)
| Node Type | IP | Port |
|---|---|---|
| Standalone | 192.168.0.21 | 5432 |
Hardware configuration: CentOS 8.5 Linux 64-bit, AMD Ryzen 9 7950X 16-Core (32 threads), MEM: 128GB, Storage: 2TB SSD (M.2 SSD PCIE 4)
PostGIS: 3.3.5
02 Performance Comparison
2.1 Test Environment Tuning
To maximize the performance of the machines' configurations and improve test results, we made appropriate adjustments to the settings in both Klustron and PostgreSQL after the initial installation, as follows:
Klustron:
Compute Nodes:
shared_buffers='32GB';
statement_timeout=600000000;
mysql_read_timeout=360000;
mysql_write_timeout=360000;
mysql_interactive_timeout=360000;
mysql_connect_timeout=100000;
mysql_wait_timeout=360000;
lock_timeout=360000000;
log_min_duration_statement=120000000;
effective_cache_size = '8GB';
work_mem = '1GB';
wal_buffers='64MB';
autovacuum=false;
metadata_connect_timeout=100000 ;
metadata_read_timeout=100000 ;
metadata_write_timeout=100000 ;
Storage Nodes:
innodb_buffer_pool_size=32*1024*1024*1024;
lock_wait_timeout=3600;
innodb_lock_wait_timeout=3600;
fullsync_timeout=1200000;
enable_fullsync=false;
innodb_flush_log_at_trx_commit=0;
sync_binlog=0;
max_binlog_size=1*1024*1024*1024;
net_read_timeout=3600 ;
net_write_timeout=3600 ;
thread_pool_queue_congest_req_timeout=3600 ;
rocksdb_lock_wait_timeout=3600 ;
delayed_insert_timeout=3600 ;
connect_timeout=3600 ;
delayed_insert_timeout=3600 ;
innodb_lock_wait_timeout=3600 ;
mysqlx_connect_timeout=3600 ;
mysqlx_read_timeout=3600 ;
mysqlx_write_timeout=3600 ;
mysqlx_wait_timeout=3600 ;
Note: Due to testing constraints, the backup nodes for the 3 storage shard nodes shared the same machines as their primaries. To mitigate resource contention, backup nodes on all three test machines were disabled via XPanel.
PostgreSQL:
shared_buffers='32GB';
statement_timeout=600000000;
lock_timeout=360000000;
log_min_duration_statement=120000000;
effective_cache_size = '8GB';
work_mem = '1GB';
wal_buffers='64MB';
autovacuum=false;
2.2 Test Data Preparation: (NYC Taxi Data)
Visit: https://github.com/toddwschneider/nyc-taxi-data/tree/master. This link includes scripts for loading New York taxi data, as well as download links for the data. Following the README instructions, both Klustron and PostgreSQL were loaded with an equal amount of data (data range: 2019-01 to 2022-11) in preparation for testing. Data preparation details are as follows:
Klustron:
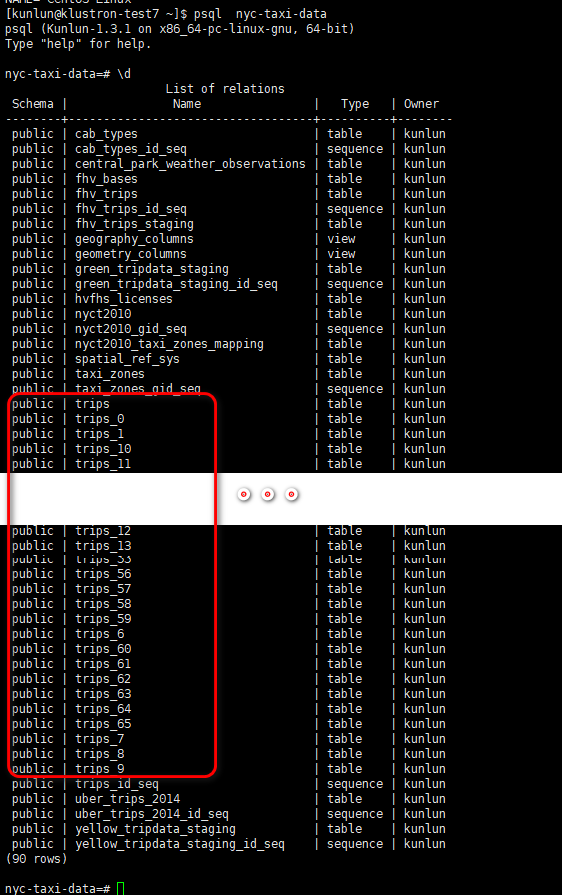
Given Klustron's 3 shards, the trips table was partitioned into 64 segments, with partition names from trips_0 to trips_65. Data was evenly distributed across 64 partitions in the 3 shard storage, totaling over 170 million records, as follows:

PostgreSQL:
As this database was a standalone environment, the trips table was not partitioned but loaded directly, with data details as follows:
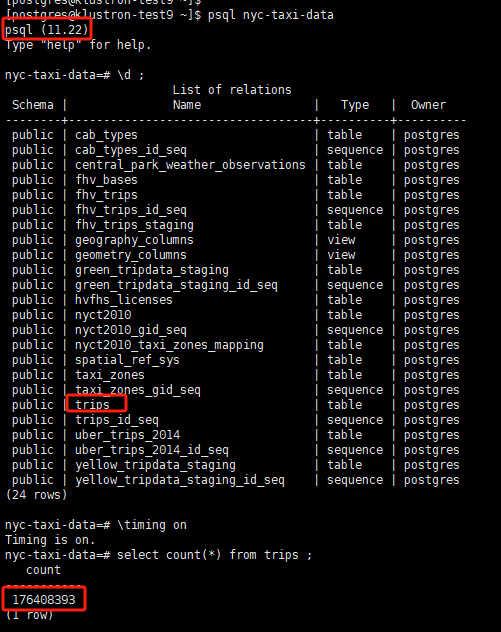
Note: Prior to testing, the trips table and related partitions in both environments were analyzed to generate statistical information, ensuring the optimizer would produce the most efficient execution plans.
2.3 Performance Test Comparison
Q1: SELECT cab_type_id, count(*) FROM trips GROUP BY cab_type_id;
Q2: SELECT passenger_count, avg(total_amount) FROM trips GROUP BY passenger_count;
Q3: SELECT passenger_count, to_char(pickup_datetime,'yyyy-mm') AS month, count(*) FROM trips GROUP BY passenger_count, month;
Q4: SELECT passenger_count, to_char(pickup_datetime,'yyyy-mm') AS month, round(trip_distance) AS distance, count(*) FROM trips GROUP BY passenger_count, month, distance ORDER BY month, count(*) DESC;
Test Results:
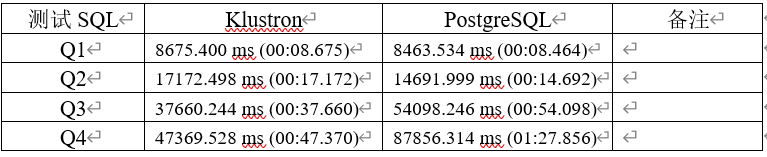
From the test results above, it's observable that in initial simple SQL tests, Klustron and PostgreSQL do not show significant performance differences. However, as the complexity of SQL increases, the performance advantages of Klustron's distributed architecture become apparent, establishing a clear lead over community PostgreSQL. It can be inferred that with further increases in data volume and SQL complexity, Klustron will demonstrate advantages in storing more data and running faster compared to community PostgreSQL.