
Introduction to Klustron’s Fullsync Mechanism
Introduction to Klustron’s Fullsync Mechanism
Key Takeaway:
The Fullsync mechanism is a high-availability feature of Klustron's storage cluster, designed to seamlessly elect a new primary node when any problem arises, ensuring the cluster continuously delivers services and achieves high availability.
As a distributed database capable of fully supporting scenarios requiring strong consistency, such as in finance and securities, Klustron's ability to provide continuous service is particularly crucial. Fullsync, a key feature for ensuring data security in Klustron, employs strong synchronization between primary and replica nodes and builds upon this with high-availability technology (Fullsync HA) to guarantee data safety even in the event of unforeseen failures.
In this session of Tech Talk, we will mainly explore the Fullsync feature and the HA technology based on it. Our goal is to not only deepen the understanding of this critical feature but also to provide a more comprehensive insight into Klustron.
01 Introduction to Klustron
First, let's briefly introduce our distributed database product Klustron. The following diagram shows the overall architecture of Klustron. As you can see, Klustron is a distributed database product with a separate storage and computation architecture.

Klustron possesses several powerful capabilities:
Elastic Scalability in Computing and Storage
- Data Partitioning (partition): hash, range, list, with any number and type of partition columns.
- Data Distribution (distribution): auto, random, mirror, table grouping.
- Automatic, flexible, non-disruptive, non-invasive, and imperceptible to end-users.
Financial-grade high reliability
- Automatically handles software, hardware, and network failures, including entire data center outages.
- Ensures data integrity and continuous service.
- Guarantees RTO < 30 seconds & RPO = 0.
- Automatically detects primary node failures, conducts primary-replica failover and leader election.
- Automatically handles software, hardware, and network failures, including entire data center outages.
HTAP: Coexistence of OLTP & OLAP:
- OLTP as the primary mode: Equivalent to using MySQL or PostgreSQL for application software.
- OLAP as a secondary mode: High performance through multi-level parallel querying.
- Flexible computing with multi-language stored procedures: ML, privacy computing.
Ecosystem compatibility:
- Supports both PostgreSQL and MySQL connection protocols and SQL syntax.
- Supports common DDL syntax of MySQL.
- Compatible with JDBC, ODBC, and common programming language clients/connectors for PostgreSQL and MySQL.
Comprehensive multi-level security
- Encrypted storage and transmission.
- Multi-level access control mechanism.
02 Why?
The need for Fullsync arises primarily from two aspects:
Business Requirements:
- Potential Failures
- Primary node hardware failure, power outages, OS restarts, process terminations;
- Disk failures or total damage in primary and replica nodes;
- Network partitions, disconnections, or congestion.
- Requirements for Financial-Grade High Reliability
- Database cluster remains readable and writable during failures (automatic detection of primary node status, automatic leader election, and failover in case of primary node failure);
- No data loss during failures;
- High performance with low latency;
- Long-term, uninterrupted cluster operation with self-maintenance.
Issues with Known Solutions:
- Semisync
- Primary node cannot rejoin the cluster after failure — rapid recovery of cluster node count is not possible;
- Replica node ACK timeout leads to automatic degradation to asynchronous, putting Consistency < Availability, failing to achieve financial-grade strong consistency;
- Lack of fsync relay log before replica node ACK; OS restarts (like data center/power outages) can lead to loss of confirmed transactions in binlog;
- Occupies working threads waiting for replica node ACK; requires launching a large number of threads when connections are high;
- Incomplete, requires external components for high availability and does not support primary node failure detection, leader election, and failover.
- MySQL Group Replication
- The primary node writes binlog to binlog files only after replica node confirms receipt, resulting in long transaction holding and waiting times before commit, significantly increasing transaction latency;
- Occupies working threads waiting for replica node ACK, necessitating a large number of threads for numerous connections.
03: Fullsync & HA
Principles of Fullsync:
- On the primary node, a transaction waits for the replica node's ACK of receiving its binlog before responding to the client (klustron-server):
- Every transaction committed on the primary node is received and persistently stored by at least one replica node (configurable).
- The timing of waiting for ACK: After the transaction completion process on the primary node and before sending the status back to the client, the transaction pipeline is already completed.
- Replica nodes collect multiple transaction binlogs, write them to the relay log file in a batch, and then flush to disk (fsync) before sending ACK.
- Statements requiring Fullsync ACK:
- All transaction commit statements with binlog.
- DDL statements, autocommit DML statements.
- Commit, XA COMMIT ... ONE PHASE.
- XA PREPARE.
The main process is illustrated in the following diagram:
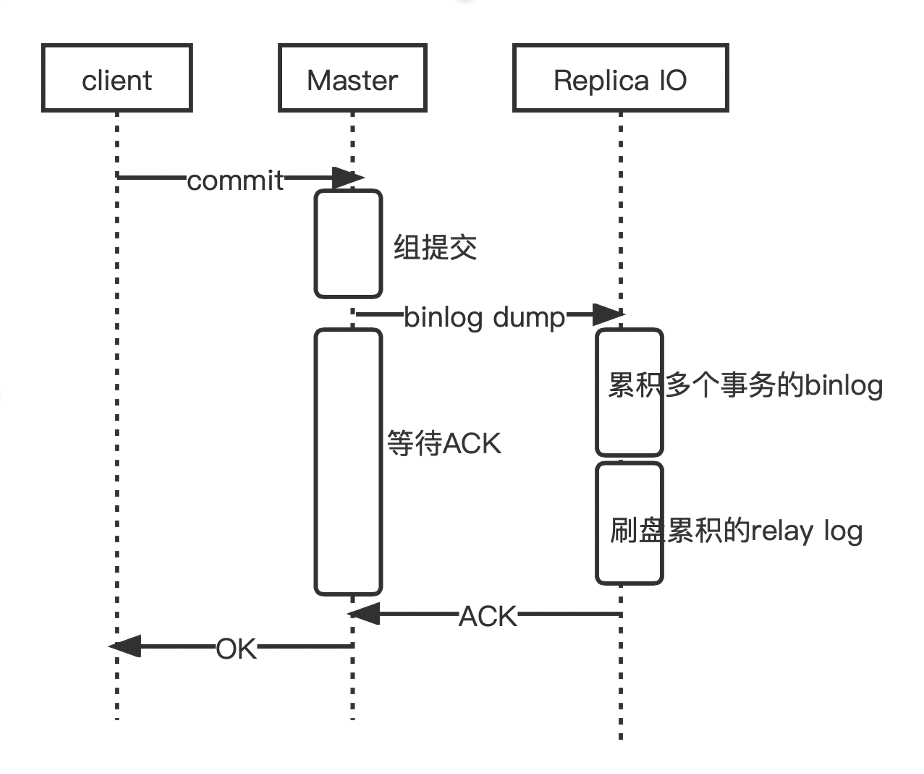
Additionally, there are some technical details:
Details of transaction waiting for Fullsync ACK on the primary node
- Waiting for: The transaction has been received and flushed to disk by enough replica nodes, with the ACK binlog position ≥ the transaction's binlog position.
- Method of waiting: Non-blocking of working threads, suspending the session (THD) until ACK arrives, allowing working threads to process other connection requests.
- Handling of waiting for ACK timeout: Fullsync HA is more robust and flexible, considering random network or IO fluctuations, with the option to prioritize either Consistency or Availability.
- Handling of received ACK: A background working thread completes the remaining transaction commit process for the targeted session (THD), sends an OK packet to the client, and the client's statement returns.
- Handling of waiting for ACK timeout: Returns a "Fullsync wait timeout" error to the client in the session.
Replica node's logic for receiving binlog
Balancing disk load, performance, and data consistency.
Write & fsync binlog by transaction: Ensuring binlog persistence even after power loss or OS restart.
ACK: A position on the primary node's binlog. Replica node sends ACK: Binlogs before this position are persistently saved, and their transactions can be successfully returned.
Method of sending ACK: SQL statement or extended client API (command sending).
SLAVE server_id CONSISTENT TO file_index offset (general log does not record this statement by default).
mysql_send_binlog_ack() (COM_BINLOG_ACK) (Faster, but requires Klustron's MySQL client lib).
Performance of Fullsync:
Based on our tests, as shown in the diagram below, the sysbench write test shows that klustron-storage fullsync is 10 times faster than the community version of MySQL MGR, and 30%-100% faster than the community version of MySQL semisync. This improvement primarily stems from two factors:
Accelerated transaction commit speeds through batch processing;
Asynchronous processing allows the primary node's working threads not to wait for the replica node's ACK, thereby speeding up the primary node's transaction processing efficiency.

Fullsync HA:
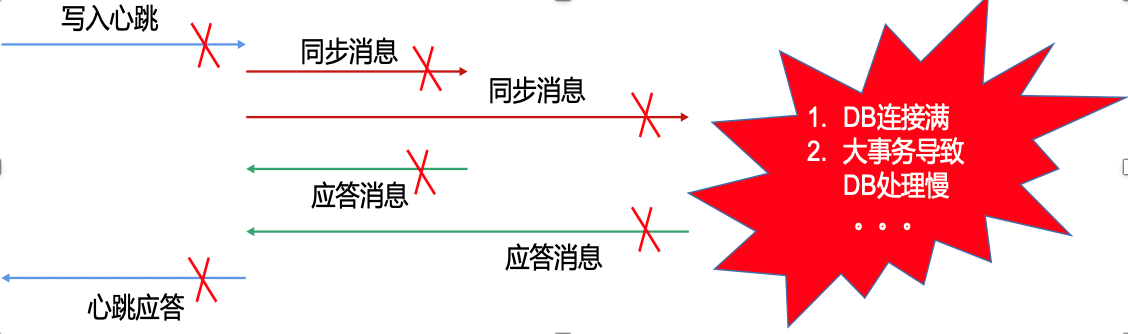
Built upon the foundation of Fullsync, Fullsync HA actively detects node failures and performs leader election and disaster recovery switching based on situations by sending heartbeat messages for fault detection. The fault detection mechanism, as illustrated in the following diagram, involves regularly sending heartbeat messages to check if nodes are functioning correctly. In case of anomalies, it initiates proactive disaster recovery switching.
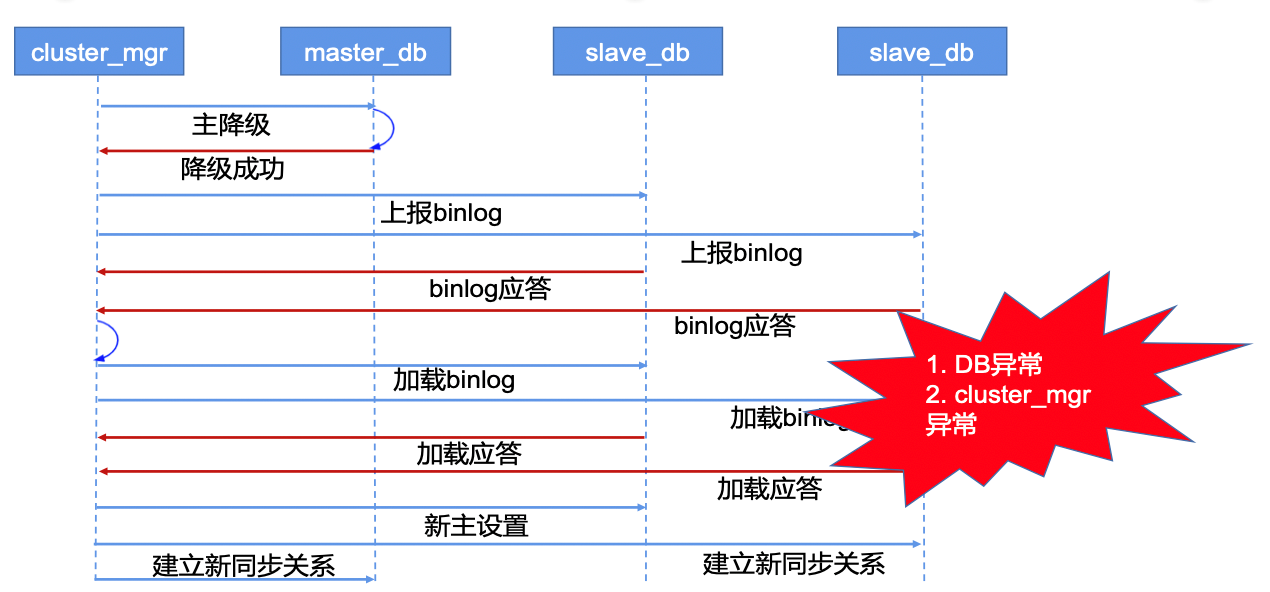
The disaster recovery switching process is shown in the diagram below. When an anomaly occurs, the problematic primary node is first demoted. Then, all its binlogs are reported and synchronized to the replica nodes. Once synchronization is complete, a new primary node is elected from among the replicas and set up. Finally, new synchronization relationships are established.
04 Q&A
Q1: Why is fullsync faster than semisync? What optimizations have you made, and how much faster is it? Why haven't the official MySQL developers made these optimizations?
A1: As we've already discussed, Klustron's enhanced performance in strong synchronization stems from two main optimizations:
Accelerated transaction commit rates through batch processing.
Efficiency in primary node transaction processing due to asynchronous handling, eliminating the need for primary node working threads to wait for replica node ACK.
Our test results show that in sysbench write tests, klustron-storage with fullsync is 10 times faster than the community version of MySQL MGR and 30%-100% faster than the community version with semisync. As for why the official developers haven't implemented these optimizations, it could be due to various reasons. They might be maintaining differentiation between the enterprise and community editions, allocating resources to higher-priority projects, or focusing on maintaining the open-source ecosystem.
Q2: Where can Klustron be tested?
A2: Those interested in Klustron can download and try it from our official website; just follow the installation guide for deployment. Additionally, we offer Klustron as a serverless service on Amazon's marketplace and Alibaba Cloud, which you are welcome to try if interested.