
Introduction of Klustron Mirror Table Functionality
Introduction of Klustron Mirror Table Functionality
Preface
Mirror tables are also known as broadcast tables or replica tables. Klustron supports Mirror table functionality to achieve better query performance.
Mirror Functionality Description
In various user business systems, some data tables have the following characteristics:
- The amount of data is relatively small, for example, less than 1GB. Most companies' personnel information tables, department information tables, organization structure tables, and even customer information tables meet this characteristic.
- The data changes infrequently. For example, a table has only thousands of insertions, updates, and other operations per day. The above examples also basically meet this characteristic.
- These tables may be connected to some huge tables (such as order tables). For these tables, users can define them as Mirror tables in Klustron to achieve better query performance.
Specifically, Klustron ensures that a Mirror table in a cluster has an identical copy of the data in each storage shard through the following methods.
- When performing insert, update, or delete operations on a Mirror table, Klustron's computing node Klustron-server will automatically perform the same data insertion, update, or deletion operation on the data copy of that Mirror table in each storage shard, and these operations run in the same global transaction, thus ensuring ACID guarantees.
- When a new storage shard is added, Klustron will automatically copy all Mirror tables in the system to the new shard. During this copying process, these Mirror tables can still be read and written, but any new Mirror table operations will be blocked until the copying is completed.
The join between Mirror tables and large tables stored in shards can always be pushed down to the storage node for execution, which ensures that the join between these two tables is executed in parallel by multiple storage nodes, thereby achieving better query performance.
In OLAP applications, dimension tables typically meet the characteristics of Mirror tables and are suitable for defining as Mirror tables. In a star-join query in OLAP, multiple Mirror tables join with a huge fact table, and they actually run in parallel on multiple storage shards because the fact table is sharded and stored on multiple (ideally all) storage shards of the cluster.
Similarly, the join of two or more Mirror tables can always be pushed down to one (less loaded) shard for execution, which can also improve query performance to some extent.
Usage example
1、Connect to the computing node of the cluster and write to the Mirror table through the computing node:
psql postgres://abc:abc@192.168.0.136:59701/postgres
create table test1(id int primary key, address char(50), number int) with (shard = all);
insert into test1(id,address,number) values(1, 'abc', 001);
insert into test1(id,address,number) values(2, '2de', 002);
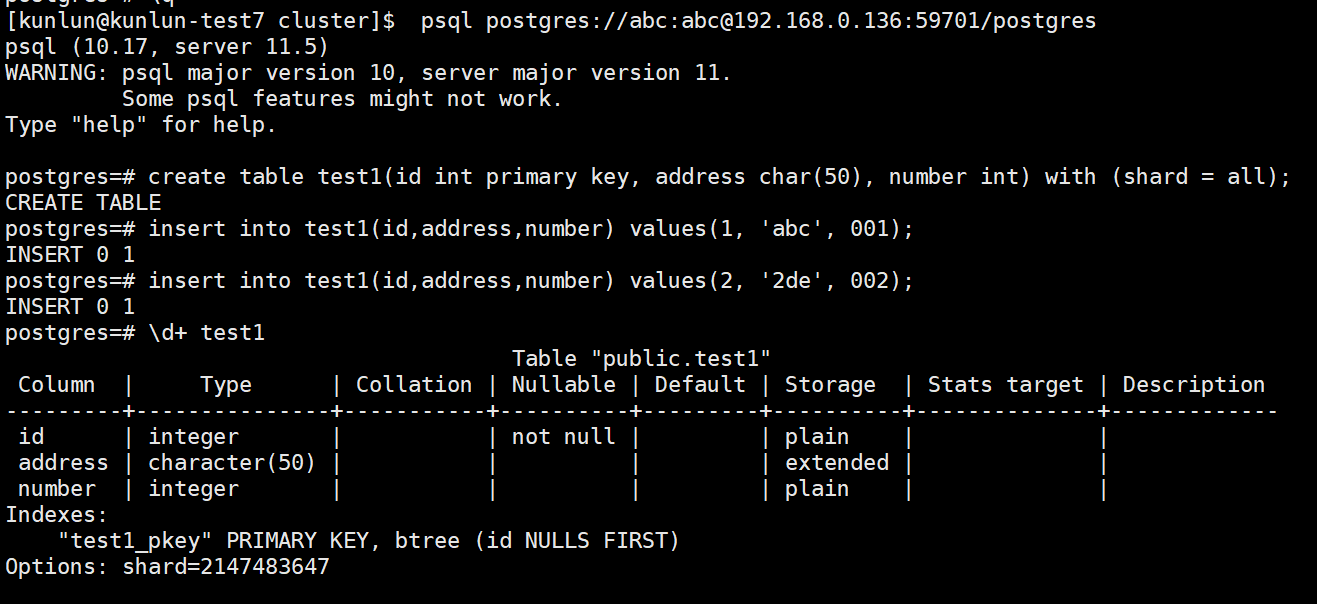
Then test1 is the Mirror table.
2、Call the add_shards interface of cluster_mgr
{
"version":"1.0",
"job_id":"",
"job_type":"add_shards",
"user_name":"kunlun_test",
"timestamp":"202205131532",
"paras":{
"cluster_id":"${cluster_id}",
"shards":"1",
"nodes":"3",
"storage_iplists":[
${storage_iplists}
]
}
}
After the add shard is successfully completed, it is found that test1 exists on the new shard and the data in the test1 table is consistent with that in pg, and the Mirror functionality is completed.