
Two-Phase Commit Mechanism and Principle for Distributed Transaction Processing
Two-Phase Commit Mechanism and Principle for Distributed Transaction Processing
1. Background
In the previous article, we reviewed the principles and defects of the classic two-phase commit algorithm. For those who are interested, you can click on the original article Principles and Defects of the Classic Two-Phase Commit Algorithm for more details.
To avoid the defects of the classic two-phase commit algorithm, Klustron's distributed transaction processing mechanism is based on the classic two-phase commit algorithm and enhances its resilience and error handling capabilities.
As a result, at any time, the Klustron cluster can withstand node failures, network failures, timeouts, and other issues without causing inconsistencies or data loss in the cluster's management.
2. Klustron's Implementation of Two-Phase Commit for Distributed Transaction Processing
Klustron's distributed transaction processing functionality involves modules distributed among the computing nodes, storage clusters, metadata clusters, and the cluster_mgr module (as shown in Figure 1).
2.1 Computing Node Module
The computing node includes the Global Transaction Manager (GTM), which maintains the internal state of each distributed transaction GT that is being executed within each client connection (i.e. Session) in a computing node. The critical information includes which storage shards the GT read and wrote, and the global transaction ID.
In Figure 1, the internal states of GT1 and GT2 are:
GT1 executed read/write operations on transaction branch T11 in storage cluster 1 and a write operation on transaction branch T12 in storage cluster 2.
GT2 executed a read operation on transaction branch T21 in storage cluster 1 and a write operation on transaction branch T22 in storage cluster 2.
The GTSS backend process in the computing node is responsible for batch writing the commit log of global transactions to the metadata cluster.
Klustron ensures that every global transaction GT with a recorded commit log will be completed. While the specific two-phase commit process is explained in detail in the following section, this section aims to provide an overview of the related modules involved.
2.2 Metadata Cluster Module
The metadata cluster is also a high-availability MySQL cluster, and its commit log records the commit decisions of each two-phase commit transaction.
These commit decisions are used by the cluster_mgr for error handling, but are rarely used in actual production system scenarios. However, this information is critical.
Only when there are failures or problems with the computing nodes or storage nodes, such as crashes or power outages, will the cluster_mgr use these commit decisions to handle prepared transaction branches that are left over.
2.3 Metadata Cluster Module
The storage cluster is a MySQL cluster, and the session (THD) object of MySQL in the storage cluster contains the state of each distributed transaction branch (referred to as XA transactions).
As shown in Figure 1, storage node 1 contains the local execution status of distributed transaction GT1 branch GT1.T11 and distributed transaction GT2 branch GT2.T21.
As shown in Figure 1, storage node 2 contains the local execution status of distributed transaction GT1 branch GT1.T12 and distributed transaction GT2 branch GT2.T22.
2.4 Cluster_mgr Module
The cluster_mgr is an independent process that works with the storage clusters and computing nodes by utilizing the metadata in the metadata cluster.
In the distributed transaction processing scenario, it is responsible for handling the prepared transaction branches that remain due to computing and/or storage node failures. It determines whether to commit or rollback each transaction branch based on the commit log of each global transaction it belongs to, as shown in Figure 1 (the details will be explained in the following section). 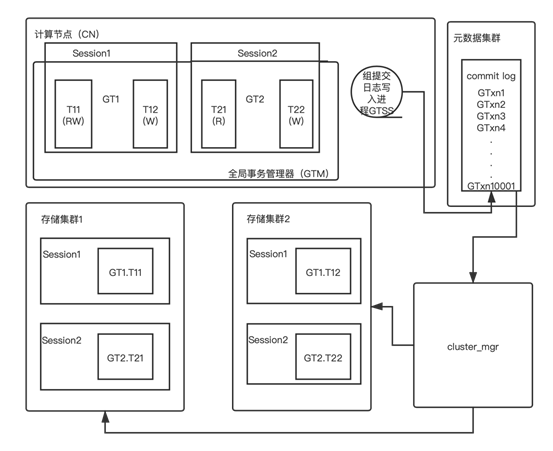
3. How is Two-Phase Commit Implemented?
When a user sends "begin transaction" to a computing node, the computing node opens a new distributed transaction GT object internally (GTM establishes an internal state for this distributed transaction GT).
Then, when the GT transaction first reads or writes to a storage cluster during its runtime, GTM sends several SQL statements, including XA START, to start GT's transaction branch in this storage cluster and initialize the transaction status.
Then DML statements are sent to read and write data. The computing node will parse, optimize, and execute the received SQL statements, and calculate which target shard to send what type of SQL statement to complete the local data read/write work. It only reads and writes storage clusters that actually contain the target data.
The communication between the computing node and a set of storage nodes is always done asynchronously to ensure that the storage nodes execute SQL statements concurrently (although this part is not the focus of this article).
If a node, network failure or partial SQL execution failure occurs in the Klustron cluster before a distributed transaction GT executes the commit, the GTM on the computing node will roll back the transaction GT and all its transaction branches on the storage nodes. The GT is then as if it had never been executed, and it will not affect user data.
Below is a detailed description of the distributed transaction commit process when the client sends a commit statement to the computing node. The normal process of transaction commit (sequence diagram) is shown in the figure below. 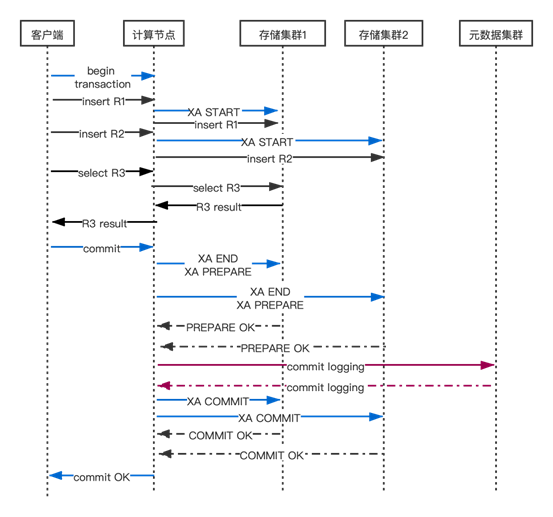
3.1 Phase One
When the client/application sends the commit statement, the GTM selects a commit strategy based on the internal state of the distributed transaction GT (when the number of storage clusters written by GT is less than 2, perform a phase one commit on all storage clusters accessed by GT).
In MySQL, this SQL statement is XA COMMIT ... ONE PHASE. If any node fails during the first phase commit of a distributed transaction, those nodes can recover locally and continue working normally, without causing any inconsistency or data corruption.
Specifically, if the failed nodes include the only node that has written data (WN), after WN completes local recovery, if the transaction branch TX of GT is recovered, then all changes of GT (all in TX) are effective. Otherwise, all changes of GT (all in TX) are not effective (in any case, the atomicity of GT is maintained).
If all the failed nodes are read-only nodes of GT, then no changes of GT are lost, and there will be no state or data inconsistency.
After the read-only storage nodes recover and complete the recovery, the undo logs remaining from the running read-only transactions will be automatically cleared by InnoDB. All other internal states during the running of read-only transactions have disappeared from memory upon restarting, so any errors during the phase one commit of read-only transactions can be safely ignored.
Therefore, the commit statement to its only write node can be executed normally in this case.
When GT writes to at least 2 storage clusters, GTM executes two-phase commit on all storage clusters that GT has written to, and executes one-phase commit on each storage cluster that GT has only read from.
During the two-phase commit, the second phase (XA COMMIT) is only executed if the first phase returns successfully for all storage clusters, otherwise the second phase executes an XA ROLLBACK command to rollback all two-phase committed transaction branches.
3.2 How to write commit log in batches?
Before starting the second phase commit, GTM requests the GTSS process to write commit logs for each GT and waits for their successful return.
Only after the GTSS has successfully written the commit log for the GT, will GTM begin the second phase of the commit. Otherwise, it will directly roll back these prepared transaction branches.
In each backend process (a backend process is a term in PostgreSQL, which refers to a process that executes SQL statements in a user connection, and each user connection is bound to a backend process), for each distributed transaction that is ready to begin the second phase of the commit, GTM puts its ID and other key information into the GTSS request queue, and waits for GTSS to notify that the request is complete.
GTSS converts all commit log write requests in the request queue into a single SQL insert statement and sends it to the metadata cluster. The metadata cluster executes the insert statement to complete commit logging and confirms success to GTSS. Then, GTSS can notify each waiting backend process to start the second phase of the commit.
If the commit log write fails, the computing node will send a rollback command (XA ROLLBACK) to the storage cluster to roll back the GT's transaction branch.
If the commit log write times out, the computing node will disconnect from the storage cluster so that the cluster_mgr module can handle it later.
All distributed transactions that confirm the writing of the commit log will definitely complete the commit. If there is a computing node or storage node failure or network disconnection, the cluster_mgr module will handle these prepared transaction branches according to the instructions in the commit log.
3.3 Will the metadata node become a performance bottleneck?
Some readers may be concerned that writing all commit logs for distributed transactions initiated by all computing nodes to the same metadata cluster could become a performance bottleneck. Would there be a single point of failure?
However, as verified and expected, the metadata cluster does not become a performance bottleneck even at an extremely high throughput of 1 million TPS.
During the full-load sysbench test with 1,000 connections, the size of the commit log batch written by the GTSS typically ranges around 200. Other workloads and related parameter configurations may result in larger or smaller batch sizes (default cluster_commitlog_group_size=8 and cluster_commitlog_delay_ms=10).
Considering that each commit log row contains less than 20 bytes of data (a fixed length independent of the workload), writing commit logs for distributed transactions from 200 storage clusters will result in a transaction that writes about 4KB of WAL logs for the metadata cluster. Therefore, even if the cluster's overall TPS reaches 1 million per second, the metadata cluster will only have a load of 5 thousand TPS, writing 20MB of WAL logs per second, which modern SSD storage devices can easily handle.
Therefore, even when the storage clusters are running at full capacity, the metadata cluster's write load remains extremely low and will not become a performance bottleneck for the Klustron cluster.
The GTSS will wait for at most cluster_commitlog_delay_ms milliseconds to collect at least cluster_commitlog_group_size transactions to send to the metadata cluster in a batch. These two parameters can be adjusted to balance the commit log batch size and transaction commit delay.
3.4 Phase Two
After the commit log is successfully written, the GTSS process notifies all user session (connection) processes waiting for the result of the commit log write, and these processes can proceed with the second phase of the transaction commit.
During the second phase, GTM sends asynchronous and parallel commit (XA COMMIT) commands to each storage node that the current distributed transaction GT has written to, and then waits for the results from these nodes.
Regardless of the result (disconnect, storage node failure), GTM returns success to the user because the start of the second phase means that the transaction will definitely complete the commit.
Even if a computing node crashes or loses network connection during the second phase, the transaction will still be committed. In this case, the backend of the application system (i.e., the database client) will notice that its commit statement has not returned until the database connection times out (usually the application layer will also allow the end user connection to time out) or returns a disconnect error.
4. Conclusion
In Klustron, our team has successfully avoided the pitfalls of the classic two-phase commit algorithm in the two-phase commit mechanism for distributed transaction processing.
In terms of the mechanism and principles of the two-phase commit for distributed transaction processing, we have improved its disaster recovery and error handling capabilities, ensuring that at any time, the failure of any node, network failure, or timeout of the Klustron cluster will not cause inconsistencies or loss of data managed by the cluster.
In the next article, we will discuss "Error Handling for Two-Phase Commit in Distributed Transactions". We welcome your feedback and discussion.