
Klustron(原KunlunBase) 数据中心(IDC) 高可用架构
Klustron(原KunlunBase) 数据中心(IDC) 高可用架构
01 Klustron IDC 高可用技术
Klustron的fullsync 强同步复制技术和fullsync HA 高可用技术,确保kunlun-storage 节点组成的存储集群(storage shard) 的主节点发生故障时,Klustron 可以自动及时发现故障并自动选举出新的主节点持续对外提供数据读写服务,并且不丢失、损坏用户数据。对于大多数应用场景所需的高可靠性要求以及能够提供的资源条件,这样的可靠性级别已经足够了。
然而面对在金融级高可靠性的极致要求,这仍然是不够的,因为如果一个数据中心(IDC)整体失效(比如断电,地震,火灾,水灾等)的情况下,如果一个Klustron 集群所有节点部署在这样一个IDC机房,它们就会同时消失,那么用户数据仍然会丢失,数据库服务也仍然会停止。
为了达到IDC 级别的高可用,Klustron 团队开发了 数据中心(IDC) 级高可用技术。Klustron 从 1.2 版本开始,支持数据中心(IDC)高可用功能。
为了便于正式介绍本文内容,先简单介绍一下Klustron的架构和基本概念。
1.1 存储集群和元数据集群高可用
Klustron 的最小容灾单元存储集群(storagae shard, 简称 shard) 是由一主多备的 Klustron-storage 集群组成。shard 内部主机负责读写请求,备机从主机流式复制数据更新,以便在主节点不可用时升级为主节点,同时还参与读写分离功能提供只读服务。主备间通过 Klustron 自研高性能高可靠 fullsync 机制来进行强同步的数据复制。Klustron Fullsync 技术确保主节点每一个事务提交时,都会受到若干个(fullsync_consistency_level 可配置参数)备机的ack才向计算节点确认事务提交成功。这样,Klustron向客户端确认提交成功的每一个事务,都有fullsync_consistency_level 个备机也受到了这个事务的数据,这些备机节点与主节点拥有相同的用户数据,可以在需要的时候升级为主节点。
Klustron storage shard的 备机角色分为两类,fullsync 备机和 async 备机。这两者的主要区别是:async备机不做强同步复制,也不参与选举;fullsync 备机做强同步复制,在既有主机故障的情况下可以被选举成为新的主机。
Klustron fullsync HA 机制会自动持续监测所有shard的主节点的运行状态,在发现某个 shard 的主机不可用的情况下,会自动选择合适的 fullsync 备机作为新的主机,此过程称为主备切换。Klustron 的主备切换是自动完成的,不需要人工介入。
Klustron 元数据集群保存了 Klustron 集群运行过程中的相关元数据,也是一个一主多备的 Klustron-storage 集群。因此在部署实践上,元数据集群本身也是一个 shard,复用 shard 的高可用能力。
1.2 计算节点高可用
一个Klustron集群可以包含若干个计算节点(Klustron-server)。Kunlun-server节点不存储用户数据,只存储元数据。所有计算节点的全部元数据信息都在元数据集群中存储和同步,并且Kunlun-server 节点在Klustron 集群运行期间会自动的持续地从元数据集群中流式拉取对元数据的更新,重放这些更新操作来更新其本地的用户元数据。因此 Kunlun-server节点属于无状态服务,可以灵活的部署在任意的物理设备上;用户可以随时增加和删除kunlun-server节点,不会丢失用户数据。
1.3 集群管理服务高可用
Klustron 的集群管理服务包含两组进程,clusterManager 和 nodeManager。它们协作完成集群高可用(fullsync HA)、水平弹性伸缩,物理/逻辑数据备份恢复、online DDL&repartition、集群节点/shard 的启停增删、手动主备切换、重做备机节点 等所有集群管理功能。
其中 clusterManager 是一个通过 raft 协议组织的高可用集群,运行在多台数据库服务器中。因此在灾难节点个数不影响多数派形成的前提下,clusterManager 服务可以自动完成切换并继续对外服务。nodeManager 是负责执行集群管理指令的服务,其部署在每个物理节点上,本身属于无状态服务,其运行时的所有元数据都从元数据集群中获取。因此 nodeManager 的高可用是通过进程监控来实现。数据库服务器的本地操作系统要确保当 nodeManager 服务退出后,其能够被及时拉起。
02 Klustron IDC 高可用容灾架构
Klustron IDC 高可用容灾架构基于 Klustron 集群组件的高可用技术实现,根据用户需求可以灵活配置部署,常见部署方式主要分为 两地三中心 及 两地四中心架构。
Klustron IDC 容灾技术可以做到如果主城的主IDC故障,则Klustron 会自动发现此故障并把每个Klustron 的storage shard的主节点自动切换到主城的(某个)备IDC 中该shard的候选主节点,这个操作简称为把这个备IDC升级为主IDC;如果主城所有IDC 全部整体故障,则用户DBA 可以收到告警并且能够手动操作Klustron XPanel GUI或者调用Klustron cluster_mgr API 来切换每个shard的主节点 到该shard在备城的备IDC 的候选主节点(此种情况下可能需要少量人工介入的操作),也就是把备城IDC升级为主IDC。
这两种操作本质上都是把一个Klustron集群的所有storage shard以及元数据集群的主节点都整体切换为另一个数据中心(IDC)中该shard的候选主节点。
应用软件平时连接主城的主IDC的计算节点,并且为了性能最优,不应该使用任何 主城备IDC或者备城IDC 中运行的计算节点。如果做了IDC切换,则主城 原来的主IDC的计算节点即使仍然能运行(通常不可以因为主IDC整体失效才会切换IDC)与 新的存储集群主节点(位于主城某个备IDC或者备城IDC)延时过大不可以继续使用。因此应用软件需要切换到连接与新主节点在同一个IDC中的那些计算节点。
计算节点的读写分离功能会根据网络延时信息自动选择合适的备节点,所以不会选择到备IDC的备节点读取数据。
2.1 两地三中心架构
两地三中心是指通过同城两个数据中心(IDC),备城一个数据中心部署实现服务的跨地域 IDC级 高可用容灾。一个 Klustron 集群的每一个 shard 的拓扑如下图所示。用户可以根据需要在每一个 IDC 部署任意数量的计算节点(Klustron-server) 和clusterManager节点。所有计算节点都持续从元数据集群同步用户的元数据更新。
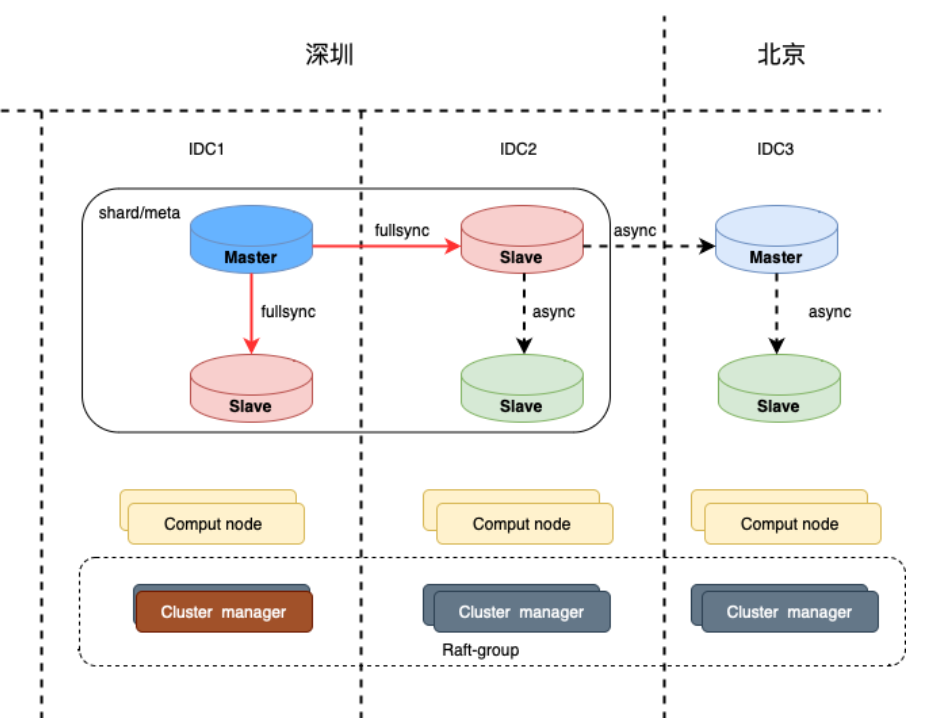
两地三中心架构实现了同城任意一个 IDC 灾难高可用自动恢复以及主城灾难下,备城IDC的手动恢复,Klustron 提供工具辅助用户切换。考虑到备城距离较远,网络延时较大,因此选择异步复制(async)到备城的备节点。
2.2 两地四中心架构
在 IDC 资源充裕的情况下,主城可以配置 3 个 IDC 来实现更加可靠的容灾。两地四中心架构可以实现同城任意两个 IDC 同时故障下的自动容灾恢复以及主城全部IDC整体灾难下的手动备城IDC恢复。
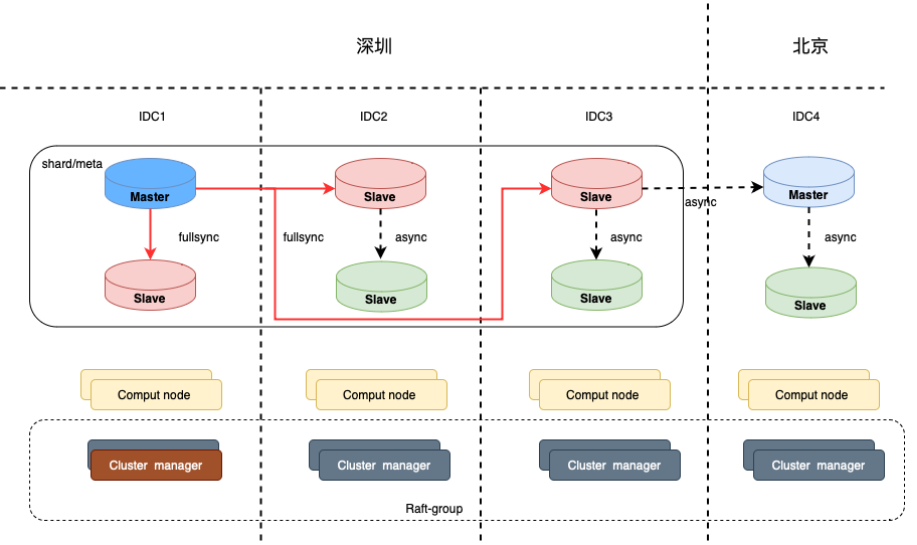
2.3 IDC容灾架构拓扑和工作原理
每个shard 在主IDC中需要有一主一备两个节点并且它们做fullsync复制,这样可以确保如果某个shard的主节点故障但是主IDC正常的情况下,Klustron会选举该shard在主IDC的fullsync备节点成为新的主节点,这样应用软件不需要切换计算节点就可以持续高效工作;
每个shard 在主城的每个备IDC都有至少两个kunlun-storage 备节点,并且其中一个从主城主IDC 的主节点做强同步复制(下文称之为 fullsync 备机或者候选主节点) ,以确保任何一个备IDC都可以切换为主IDC -- 这要求每个shard在这个备IDC都有候选节点可以立刻成为新的主节点;同时,备IDC中每个shard的另一个备节点从 本shard在同IDC 的 候选主节点 做异步复制。
如果主IDC整体故障,Klustron能够自动发现这种故障情况,并为每个shard 自动选举 该shard在主城某个备IDC的 候选主节点成为该shard新的主节点,这个备IDC也就升级为新的主IDC。新的主IDC中每个shard的候选主节点升级为主节点后,它与同IDC内本shard的另一个备机节点的异步复制也会升级为fullsync复制,并且该shard在其他(主城或者备城)备IDC的候选主节点都改为从这个新的主节点复制数据更新,原来是fullsync 复制的依然是fullsync复制,原来是异步复制(async) 的依然是异步复制。这样的IDC切换可以保持数据一致性,不会丢失、损坏数据。
如果主城所有IDC全部故障,则用户可以使用Klustron 的功能接口手动切换到了备城的IDC。由于物理距离遥远,网络包传输时耗太大,每个shard在备城IDC的 候选主节点只能从该shard在主IDC的主节点做异步复制,所以这样的IDC切换还意味着用户有可能丢失灾难发生之前的少量最新的数据更新 和/或 元数据更新(如果故障发生前刚好在执行DDL的话),也就是意味着切换后集群可能因为元数据和数据不匹配而无法正常工作,此时就需要DBA人工介入修复数据。
IDC切换发生后,应用软件务必也切换到使用新的主 IDC内的计算节点,因为老的主IDC的计算节点也都不可用了。这个切换需要用户自己实现,比如使用负载均衡等工具。
可以看出两地三中心和两地四中心唯一的区别就是增加了一个主城的备IDC。用户可以按照需要,增加更多的备IDC在主城 和/或 备城,只要为每个shard 复制相同的备IDC 拓扑结构即可。并且用户还可以增加更多的备城,在其中设置一个或者多个IDC。当然,只要是升级 备城的IDC 成为 主IDC,那么都需要手动操作。