
TABLEGROUP 功能和用法说明
TABLEGROUP 功能和用法说明
为什么需要TABLEGROUP:
在实践中,有些表经常做表连接,或者经常在同一个事务中更新,因此Klustron支持用户把这些表始终放在同一个shard,以便得到更好的查询性能和事务处理性能。为此,Klustron实现了TABLEGROUP功能,让用户把这些紧密相关的表放到一个TABLEGROUP中,以便执行组内表连接时可以将表连接下推到存储分片中,同一个事务中更新这些表可以避免两阶段提交,从而获得更好的性能。一个TABLEGROUP中的表不可以单独搬迁到另一个shard,如果要搬迁必须做tablegroup 整体搬迁。在用户应用程序系统中可以有多个表组(集群),以及一些不在任何组中的表。
Klustron提供了完整的语法来创建和管理TABLEGROUP.
CREATE TABLEGROUP --可以指定表组的名称、拥有者以及其存放的分片
可以指定表组的名称、拥有者以及其存放的分片;如果没有指定分片,计算节点将自动为其分配一个。
大纲:
{{{
CREATE TABLEGROUP name
[ OWNER { new_owner | CURRENT_USER | SESSION_USER } ]
[ WITH (SHARD = shardid) ]
}}}
从Klustron-1.4开始,支持如下语法:
CREATE TABLEGROUP name
PARTITIONS ICONST { TableGroupPartitionSpec [, ... ] }
TableGroupPartitionSpec: PARTITION part_name WITH(hash=HC, shard=N)
HC是hash分区的hash code,N是storage shard ID,可以从计算节点的pg_shard中查到。
此语法的作用是便利化的处理一组经常关联的并且按照hash分区方式分区的表,把它们的具有相同hash值的分区放置在相同的shard上面,以便后续做join时可以下推到各个shard执行。见下文详述。
查看:
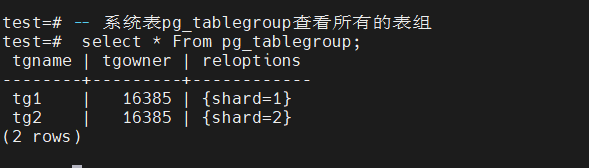
-- 系统表pg_tablegroup查看所有的表组
select * From pg_tablegroup ;
-- 访问视图information_schema.tablegroup,获取所有绑定的编组的表
select * from information_schema.tablegroup;

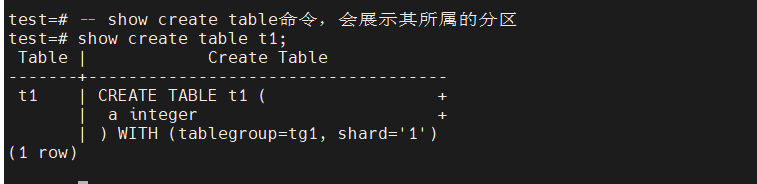
-- show create table命令,会展示其所属的分区
show create table t1;
示例:
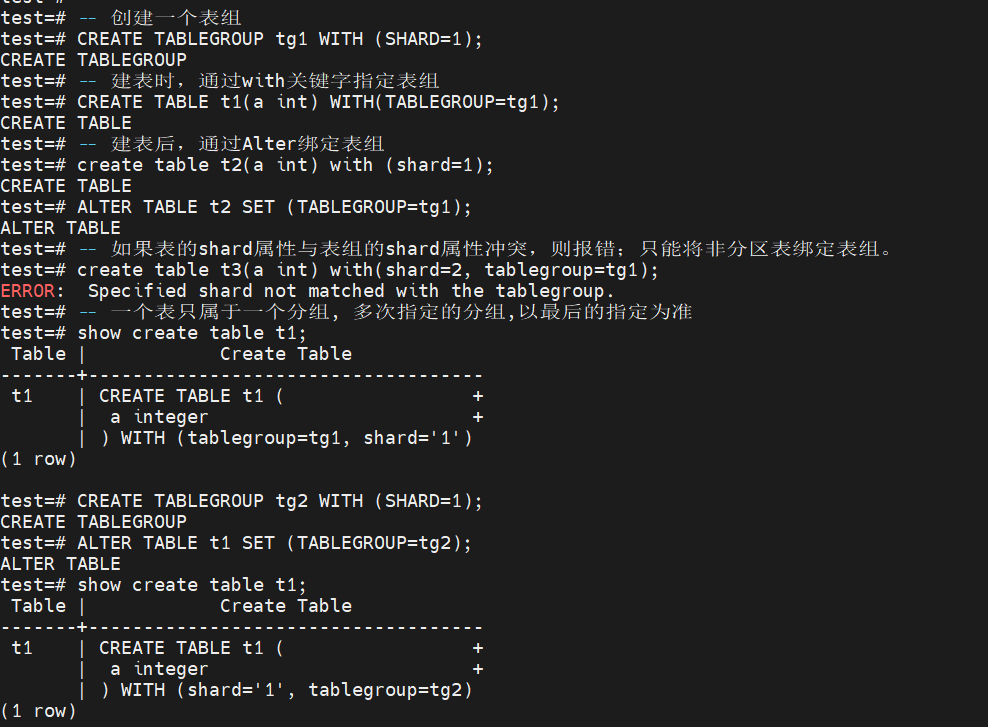
绑定表组:
{{{
-- 创建一个表组
CREATE TABLEGROUP tg1 WITH (SHARD=1);
-- 建表时,通过with关键字指定表组
CREATE TABLE t1(a int) WITH(TABLEGROUP=tg1);
-- 建表后,通过Alter绑定表组
create table t2(a int) with (shard=1);
ALTER TABLE t2 SET (TABLEGROUP=tg1);
-- 如果表的shard属性与表组的shard属性冲突,则报错;只能将非分区表绑定表组。
create table t3(a int) with(shard=2, tablegroup=tg1);
ERROR: Specified shard not matched with the tablegroup.
-- 一个表只属于一个分组, 多次指定的分组,以最后的指定为准
show create table t1;
CREATE TABLEGROUP tg2 WITH (SHARD=1);
ALTER TABLE t1 SET (TABLEGROUP=tg2);
show create table t1;
}}}
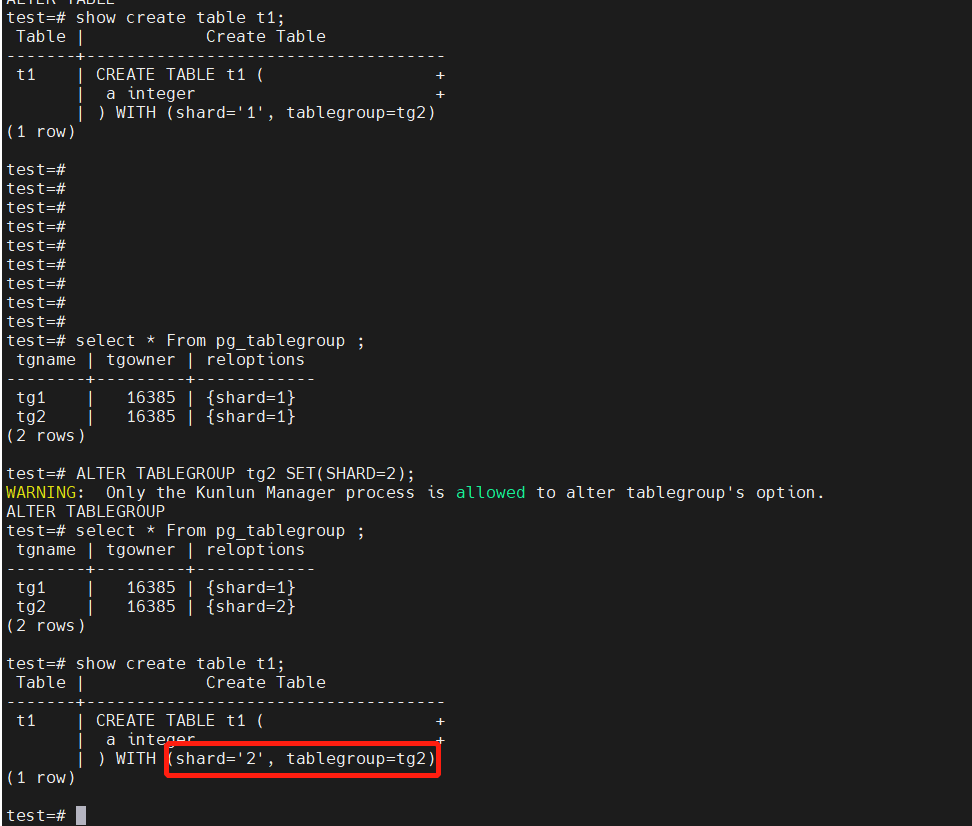
修改分片:
{{{
-- 修改表组所在分片(用于移动表组之后,修改表组的元数据);
-- 属于该表组的所有表的元数据也很会被同步修改。
select * From pg_tablegroup ;
ALTER TABLEGROUP tg2 SET(SHARD=2);
select * From pg_tablegroup ;
show create table t1;
}}}
解绑:
{{{
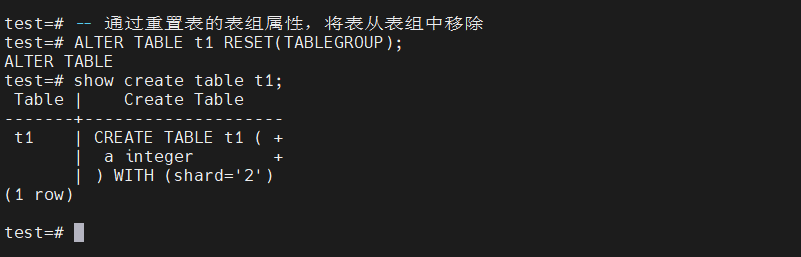
-- 通过重置表的表组属性,将表从表组中移除
ALTER TABLE t1 RESET(TABLEGROUP);
show create table t1;
}}}
删除:
{{{
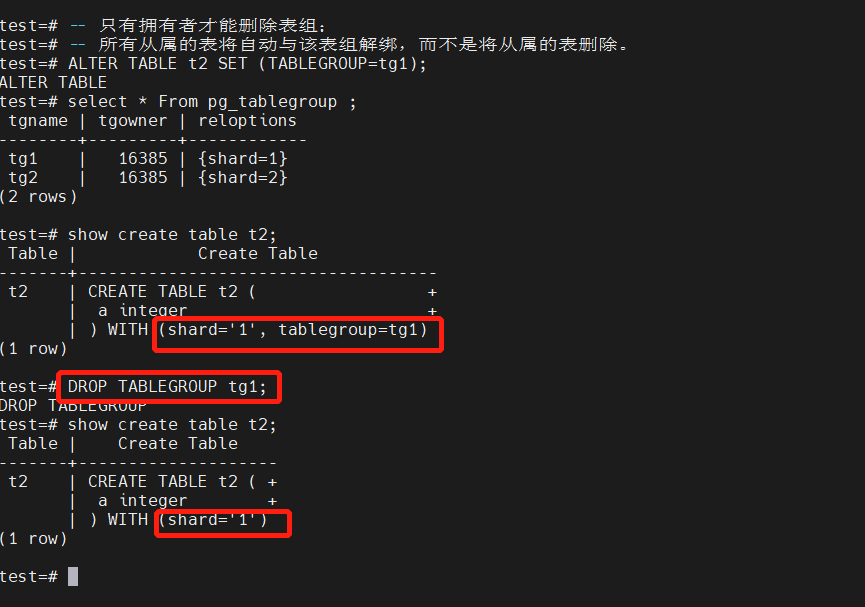
-- 只有拥有者才能删除表组;
-- 所有从属的表将自动与该表组解绑,而不是将从属的表删除。
ALTER TABLE t2 SET (TABLEGROUP=tg1);
select * From pg_tablegroup ;
show create table t2;
DROP TABLEGROUP tg1;
show create table t2;
}}}
回档
支持remap_shardid类型ddl事件,用于在回档集群时调整表以及表组的shard属性。
pg_dump导出

便利地创建hash分区表并且安排其shard以便做join下推
下面的例子中, 先创建PART,SUPPLIER这两个分区表. 由于经常要做PART.p_partkey=SUPPLIER.s_suppkey的关联查询, 所以决定把它们都创建为HASH分区表并且都有3个分区, 并且hash 余数值相同的分区位于同一个shard,以便下推join到存储节点执行。
为此先创建tpch10这个table group, tpc10规定了其中的每个hash分区表的hash 值为0、1、2的分区分别位于shard 编号为1、2、3 的shard。然后创建PART, SUPPLIER,指定其TABLEGROUP为tpch10, 这样part和SUPPLIER的3个hash分区都会按照tpc10指定的方式来创建和存储。
即时不使用TABLE GROUP 语法也可以达到上述分区表放置安排,不过需要写更多的SQL语句。这两种方式的完整示例参考这篇文章
create TABLEGROUP tpch10 partitions 3 (
partition tpch10_auto_p0 with(hash=0,shard=1),
partition tpch10_auto_p1 with(hash=1,shard=2),
partition tpch10_auto_p2 with(hash=2,shard=3)
);
CREATE TABLE PART ( P_PARTKEY INTEGER NOT NULL,
P_NAME VARCHAR(55) NOT NULL,
P_MFGR CHAR(25) NOT NULL,
P_BRAND CHAR(10) NOT NULL,
P_TYPE VARCHAR(25) NOT NULL,
P_SIZE INTEGER NOT NULL,
P_CONTAINER CHAR(10) NOT NULL,
P_RETAILPRICE double NOT NULL,
P_COMMENT VARCHAR(23) NOT NULL,
PRIMARY KEY (p_partkey)) PARTITION BY HASH (p_partkey) partitions 3 TABLEGROUP tpch10;
CREATE TABLE SUPPLIER ( S_SUPPKEY INTEGER NOT NULL,
S_NAME CHAR(25) NOT NULL,
S_ADDRESS VARCHAR(40) NOT NULL,
S_NATIONKEY INTEGER NOT NULL,
S_PHONE CHAR(15) NOT NULL,
S_ACCTBAL double NOT NULL,
S_COMMENT VARCHAR(101) NOT NULL,
PRIMARY KEY (s_suppkey)) PARTITION BY HASH (s_suppkey) partitions 3 TABLEGROUP tpch10;