
Klustron(KunlunBase) Mirror 表功能介绍
Klustron(KunlunBase) Mirror 表功能介绍
前言
Mirror 表也被称为镜像表、广播表、复制表。Klustron 支持 Mirror 表功能,以实现更好的查询性能。
Mirror 功能描述
各种用户的业务系统中,通常有一些数据表具有如下特征:
数据量比较小,例如小于 1GB。大多数公司的人员信息表、部门信息表、组织结构表、甚至客户信息表,都符合这种特点
数据变化不频繁。例如每天一个表只有数千次插入、更新等操作。上述例子也基本符合这条特征。
这些表可能与某些巨大的表(比如订单表)做连接。对于这些表,在 Klustron 中用户可以把他们定义为 Mirror 表(镜像表),以便实现更好的查询性能。
具体来说,Klustron 会确保一个集群的 Mirror 表在每一个存储集群(storage shard)中都有一份相同的数据,通过如下方法实现。
- 执行对一个 Mirror 表的插入、更新、删除操作时,Klustron 的计算节点 Klustron-server 会自动对这个 Mirror 表在每一个存储集群的那份数据做相同的数据插入、更新、删除操作,并且这些操作运行在同一个全局事务中,因而具有ACID保障。
也正因此,如果一个表更新非常频繁,那么在一个分布式事务中更新所有shard上这个mirror表的副本的话,就会严重影响性能,因此可能就不适合作为mirror表。这是一个比较宽泛的经验规则,用户可以根据这些考虑来自行决定。
- 新增一个存储集群时,Klustron 会自动把系统中所有的 Mirror 表都复制到新shard上,在这个复制的过程中,这些 Mirror 表仍然可以被读写,不过新增 Mirror 表的操作会阻塞直到复制全部完成。
Mirror 表与分片存储的大表的 join 就总是可以下推到存储节点执行,同时这确保了这两个表的 join 是由多个存储节点并行执行的,从而达到更好的查询执行性能。
在 OLAP 应用中,维度表通常符合 Mirror 表的特征,适合定义为 Mirror 表。这样在一个 OLAP 的星形连接查询中,多个 Mirror 表与一个巨大的事实表的的 join,实际上也是并行地运行在多个 storage shard 的,因为这个事实表会分片存储到多个(最好是集群所有的)storage shard。
同时,两个或者多个 Mirror 表的 join,也总是可以下推到某一个(负载较低的) shard 去执行,也可以在一定程度上提升查询性能。
使用示例
1、连接集群的计算节点,通过计算节点写入 Mirror table:
psql postgres://abc:abc@192.168.0.136:59701/postgres
create table test1(id int primary key, address char(50), number int) with (shard = all);
insert into test1(id,address,number) values(1, 'abc', 001);
insert into test1(id,address,number) values(2, '2de', 002);
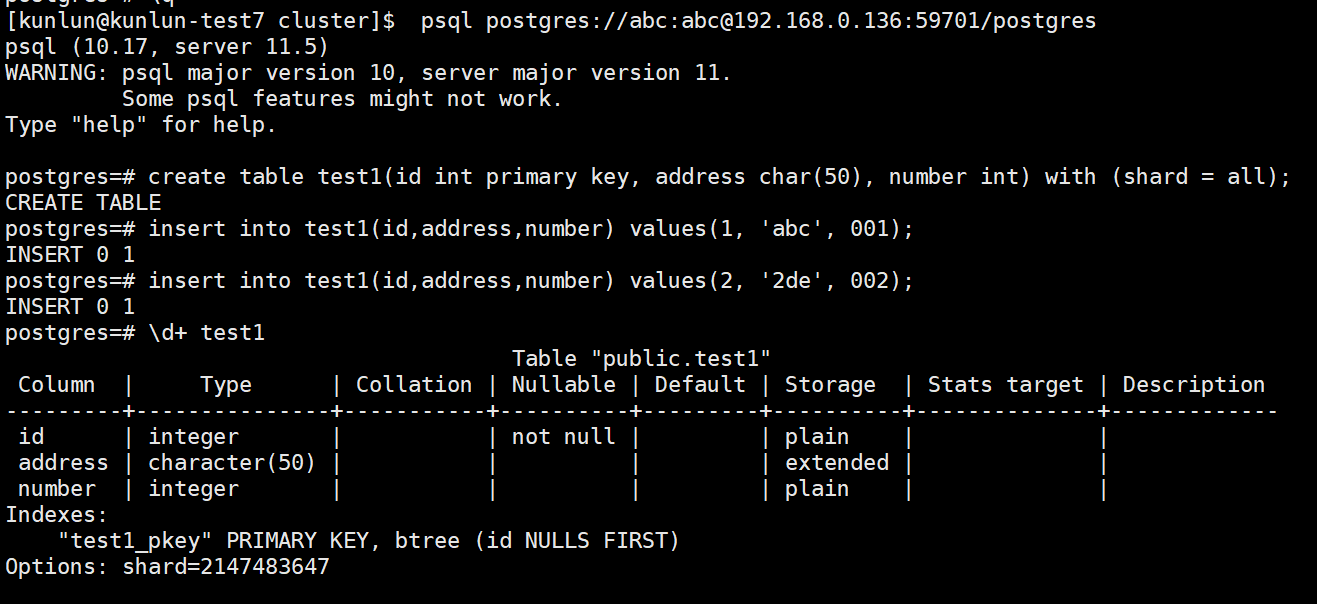 则 test1 即为 Mirror table。
则 test1 即为 Mirror table。
2、调用 cluster_mgr 的 add_shards 接口
{
"version":"1.0",
"job_id":"",
"job_type":"add_shards",
"user_name":"kunlun_test",
"timestamp":"202205131532",
"paras":{
"cluster_id":"${cluster_id}",
"shards":"1",
"nodes":"3",
"storage_iplists":[
${storage_iplists}
]
}
}
add shard 成功完成后,发现新 shard 上存在 test1,且 test1 表中数据与 pg 中一致,则 Mirror 功能完成。